Large Language Models Enter the 3D World!
An overview of the first 3D-LLM


Watch the video
We’ve seen large language models, we’ve seen them work with text, with code, with images, but one thing they lack is to work in our world. What I mean by that is being able to understand our world as we see it and not just through text and images, which are just two specific ways we can describe our world. Well, today, we make a big jump forward with 3D-LLM.
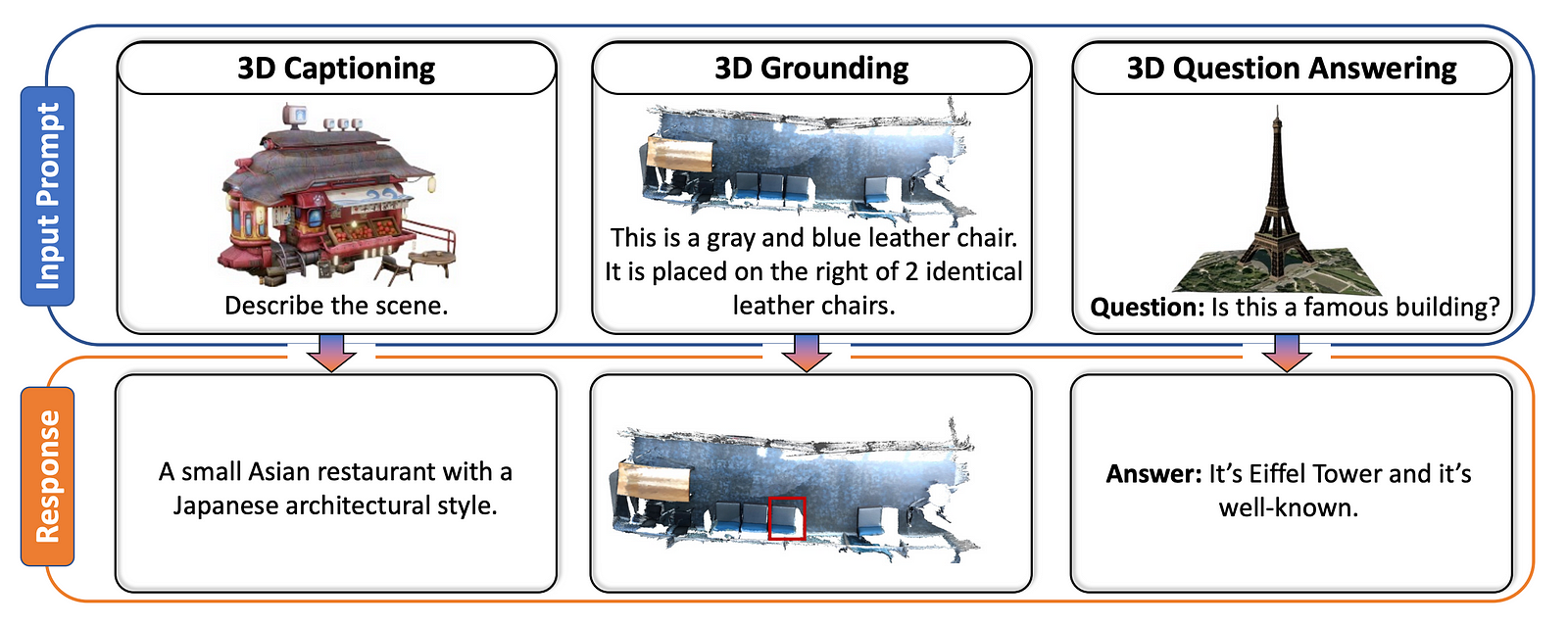
3D-LLM is a new model you can interact with that is able to understand our world. Well, still part of it since it only is able to understand the 3 dimensions and text, which is not all of it, but still a very important chunk of what we experience in our lives. As you see in the examples above and below, you can ask it any questions related to the environment, and it will answer them with very good commonsense reasoning that the usual LLMs have. Of course, it’s not perfect, but as you know from ChatGPT, it is impressive. It won’t only see the world and answer questions, but you can also interact with the world it sees or ask it to find its way to a specific room or object. You can ask about specific objects, point to things, etc. It is, to my knowledge, the first LLM really interacting with the world we live in, which is pretty cool.
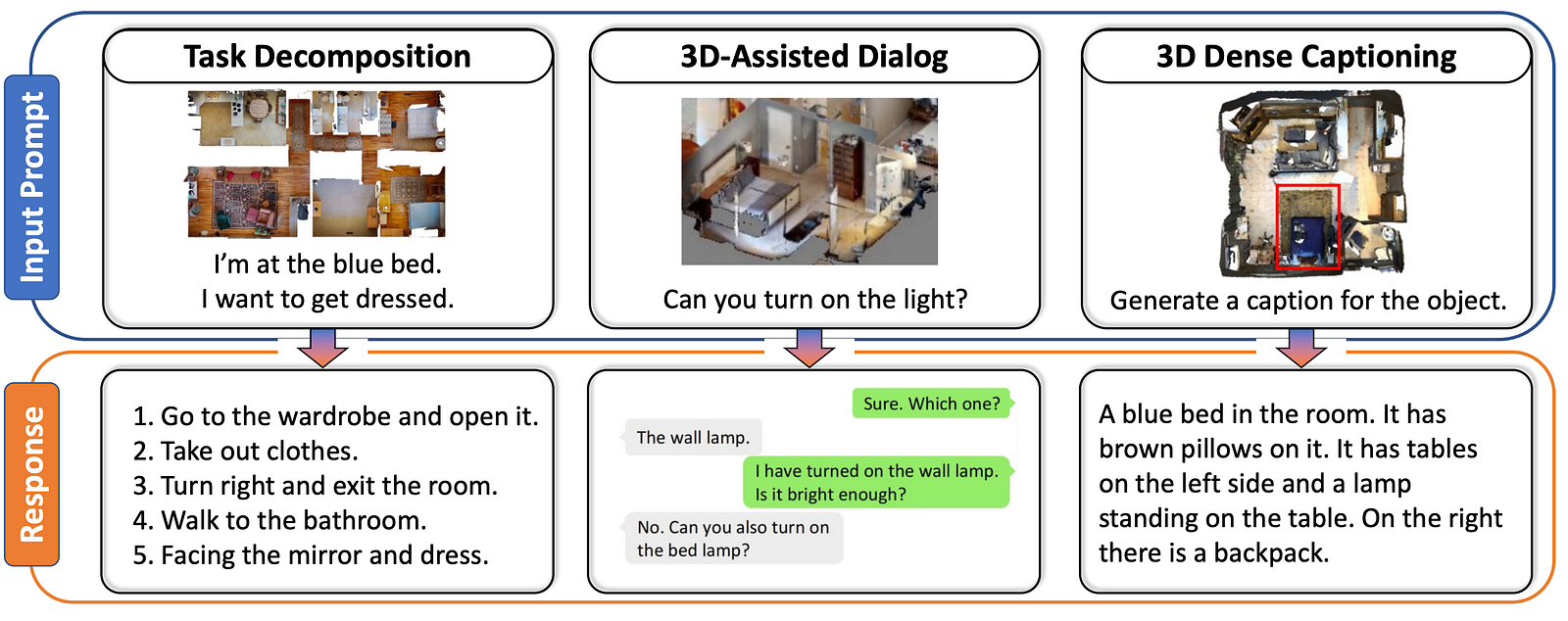
As you see, the world it sees is quite ugly. This is because the model is only able to understand point clouds and language. Point clouds are collections of 3D data points representing spatial coordinates of objects or environments. In AI for 3D scenes, point clouds are used as an efficient data representation. It’s used a lot in autonomous driving, robotics, or augmented reality, where they enable AI models to perceive and interact with the real world in three dimensions.
But how could they train such a model to work with 3-dimensional data and language? Usually, just to match images to text, you need lots of examples of text-image pairs so that the model can understand both modalities and their resemblances. And those are quite easy to find on the internet.
They had to do exactly that: build a new dataset with 3D-text pairs. And how did they do that? Well, just like us, when we don’t know the answer nowadays, they asked ChatGPT! They wanted a few different types of data, so they have three ways to prompt a text-only GPT model for generating the data they needed. The first one is the “Box-Demonstration-Instruction based Prompting”. Here they provide information about the semantics and spatial locations of the scene along with bounding boxes of the rooms and objects in it. Then, they provided specific instructions to the GPT model to generate diverse data, like giving it a role to play as and a task to achieve. They also provided the model with some examples of what they expected, which is something you can do with ChatGPT to get better results.

They also used another approach where they would take multiple photos of the 3D scenes as well as a question and use ChatGPT to ask questions and collect information about the scene with the goal of understanding it. Here, another very powerful model called BLIP-2 would answer ChatGPT since it has been trained with both images and text with this purpose of answering questions about the images.
Lastly, the third kind of data they produced is to generate question and answer pairs from text descriptions of scenes we had. This will be helpful for the model to be able to see more examples of the questions it might be prompted with.
https://louisbouchard.substack.com/
Thanks to these three different generation steps, the authors built a very complete and general dataset with multiple tasks and examples for each scene they had. Now that we have our dataset, we need an AI model to process both text and those 3D point clouds and train it!
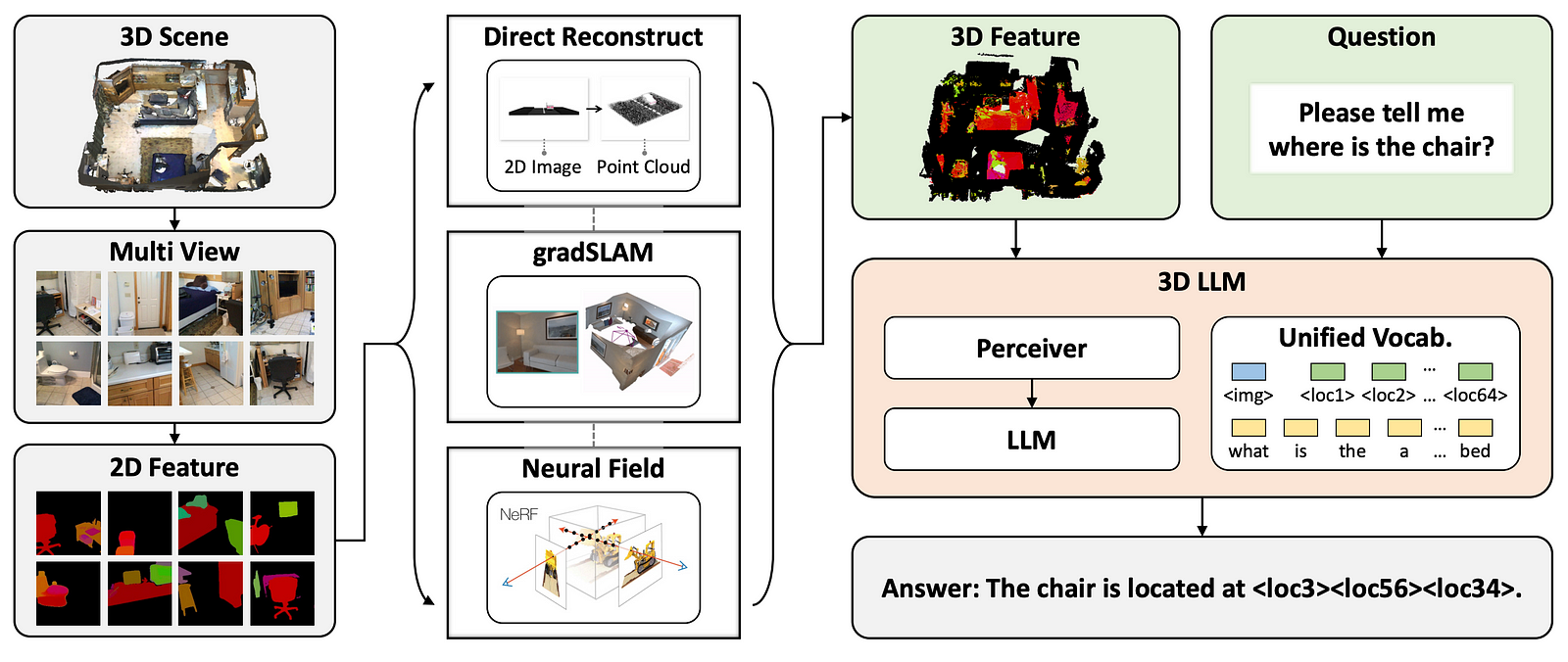
To start, we need the model to see and understand the scene. Usually, for images, we use something like CLIP which is a model able to extract features from the images that are similar to text features, which allows us to compare the image with text and understand it. Here it works a bit differently since we don’t have a CLIP model in 3D trained with billions of images. We take the 3D points and extract their important features by rendering the scene in different views, basically taking many pictures of it. Then, depending on the type of 3D data we have as input, they use one of these techniques to reconstruct the scene in a way the model understands it. I invite you to read the paper for a deeper explanation of each method and why they use it. Then, they end up with again a scene made of 3D points. But now the scene is different. Thanks to the images we took of the scene, we were able to segment them and get all the objects present in the scene, which we can then simply match on the new reconstruction.
Now that we have our scene with object understanding, we can send it our question. Now the goal is to do just like BLIP-2 or CLIP and match the text with the scene, which is the 3D LLM part. The challenge here is that the scenes and texts are of varying sizes and complexity compared to images that we can normalize. They thus use a model called Perceiver, which is basically a Transformer model, so the same ones as those behind GPT with the difference that it works with any input size and is used here to process the information of varying sizes and translate it into a fixed-size representation, which can then be sent to a pre-trained vision-LLM. It basically acts as a translator from the 3D scene to the 2D world that the LLM will understand. The perceiver’s response is then processed by our LLM into proper language. Thanks to a long training process and the dataset they have built, you end up with the answer to your question!
And voilà! This is how the first 3D-LLM is born and sees our world. Of course, this was just an overview of this new paper, and I definitely invite you to read it for more details on the implementation as there are a lot of engineering prowesses the authors did to make this work, which I omitted for simplicity here. The link is in the references below. Also, I show many more results in the video!
I hope you’ve enjoyed the article, and I will see you next time with another amazing paper!
References
Project page with video demo: https://vis-www.cs.umass.edu/3dllm/
Code:https://github.com/UMass-Foundation-Model/3D-LLM
Paper: Hong et al., 2023: 3D-LLM, https://arxiv.org/pdf/2307.12981.pdf