High-Resolution Photorealistic Image Translation in Real-Time
Apply any style to your 4K image in real-time using this new machine learning-based approach!


Watch the video and support me on YouTube!
You've all seen these kinds of pictures where a person's face is "toonified" into an anime character.

Many of you must have seen other kinds of image transformations like this, where an image is changed to follow the style of a certain artist.
Here, an even more challenging task could be something like this, where an image is transformed into another season or time of the day.


What you have not seen yet is the time it takes to produce these results and the actual resolutions of the produced pictures. This new paper is completely transparent towards this as it attacks exactly this problem. Indeed, compared to most approaches, they translate high-definition 4K images, and this is done in real-time. In this work, they showed their results on season translation, night and day translations, and photo retouching, which you've been looking at just above. This task is also known as 'image-to-image translation', and all the results you see here were produced in 4K. Of course, the images here were taken from their paper, so it might not look that high-quality here. Please look at their paper or try their code if you are not convinced!
These are the most amazing results of this paper:
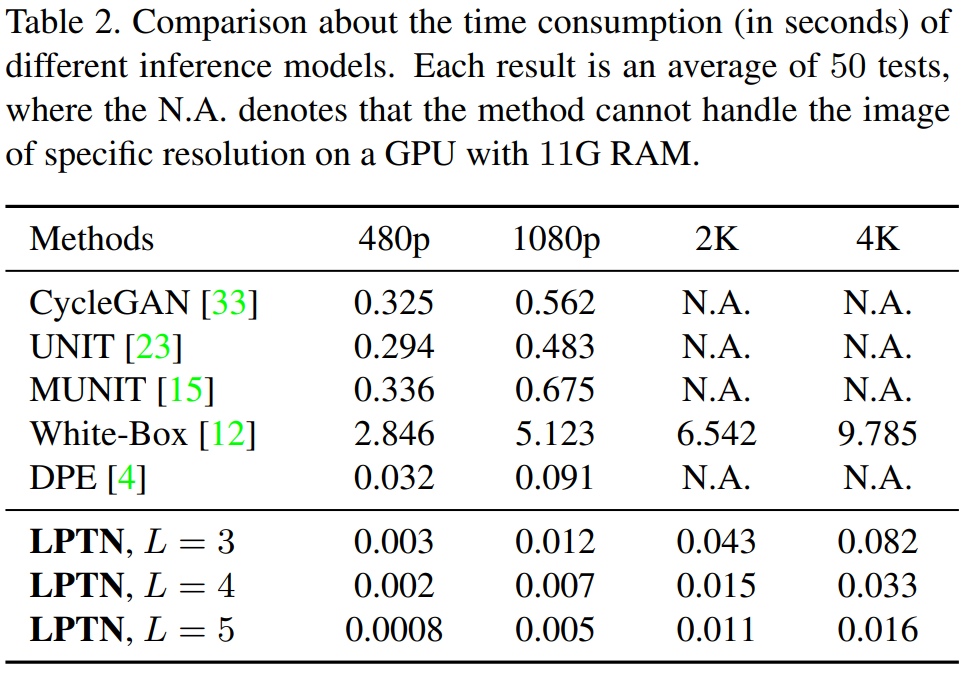
Here, you can see their technique below called LPTN, which stands for Laplacian Pyramid Translation Network. Look at how much less time it took LPTN to produce the image translations where most approaches cannot even do it as this amount of definition is just too computationally demanding. And yes, this is in seconds. They could translate 4K images in not even a tenth of a second using a single regular GPU. It is faster than all these approaches on 480p image translations! And yes, it is not eight times faster, but 80 times faster on average! But how is that possible? How can they be so much more efficient and still produce amazing and high-quality results?
This is achieved by optimizing the fact that illumination and color manipulation, which relates to the style of an image, is contained in the low-frequency component of an image.

Whereas the content details, which we want to keep when translating an image into another style, can be adaptively refined on high-frequency components. This is where it becomes interesting. These two components can be divided into two tasks that can be performed simultaneously by the GPU. Indeed, they split the image into low-resolution and high-resolution components, use a network to process the information of the low-frequency or the style of the image, and render a final image merging this processed style with the refined high-frequency component, which is the details of the image but adapted by a smaller sub-network to fit the new style. Thus dodging the unavoidable heavy computation consumption when processing the high-resolution components in the whole network. This has been a long-standing studied field achieved with a popular technique called Laplacian Pyramid. The main idea of this Laplacian Pyramid method is to decompose the image into high and low-frequency segments and reconstruct it afterward.
First, we produce an average of the initial image, making it blurry and removing high-frequency components.

This is done using a kernel that passes through the whole image to round batches of pixels together. For example, if they take a 3 by 3 kernel, it would go through the whole image averaging 3 by 3 patches removing all unique values. They are basically blurring the image by softening the edges.

Then, the difference between this blurry image and the initial image is saved to use at the end of the algorithm to re-introduce the details, which are the high-frequency components. This is repeated three times with bigger and bigger averaging kernels producing smaller and smaller low-frequency versions of the image having less and less high-frequency details.
If you remember, these low-frequency versions of the image contain information about the colors in the image and illumination. Indeed, they are basically just a blurred low-quality version of our image, which is why the model is so much more efficient. This is convenient since they are smaller versions of the image, and this is the exact information we are trying to change when translating the image into another style.

Meaning that using these low-frequency versions is much more computationally efficient than using the whole image directly, but they are also focused on the information we want to change in the image, which is why the results are so great.
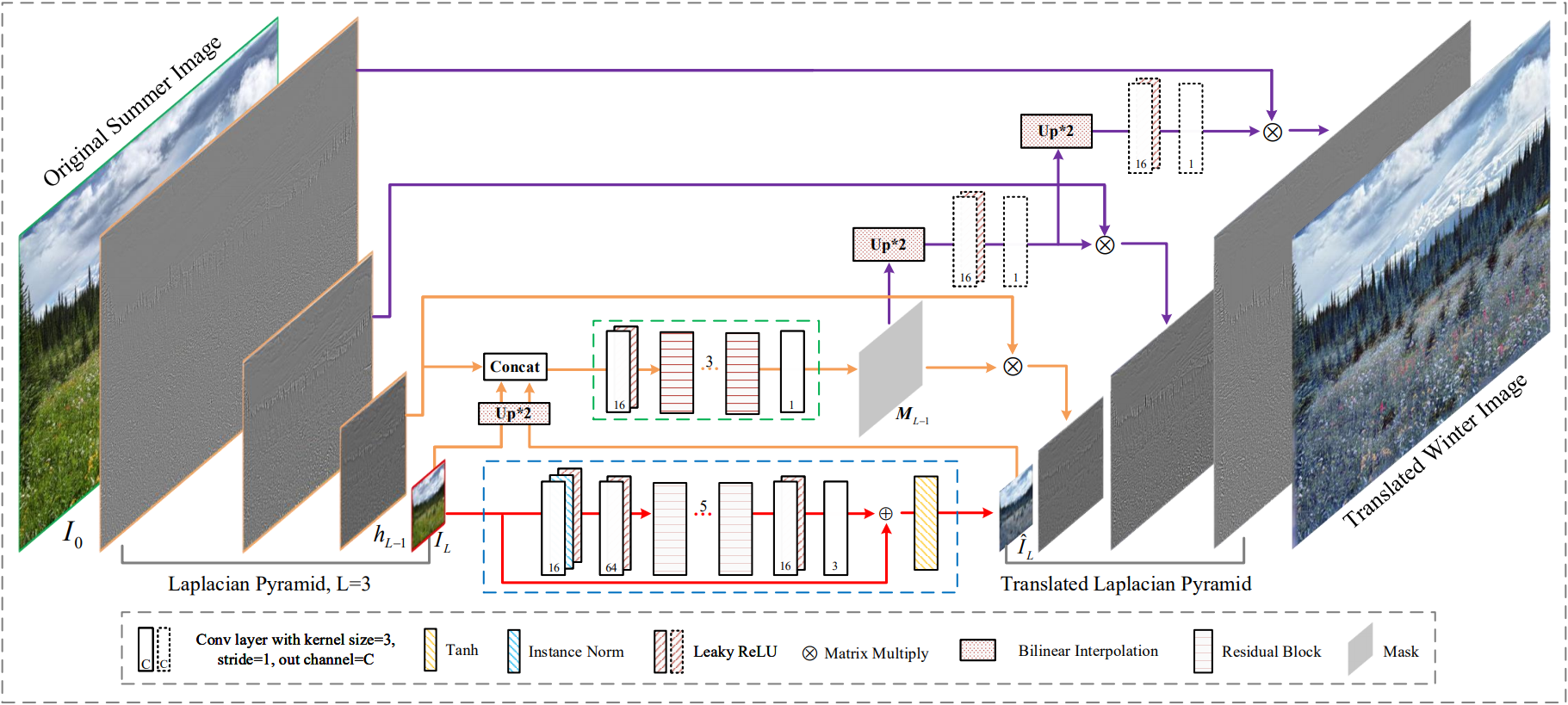
This lower-quality version of the image can be easily translated using an encoder-decoder, just like any other image translation technique we previously mentioned, but since it is done on a much lower quality image and a much smaller image, it is exponentially faster to process. The best thing is that the quality of the results only depends on the initially saved high-frequency versions of the image sent as input which is not processed throughout the whole network. This high-frequency information is simply merged at the end of the processing with the low-frequency image to improve the details. Basically, it is so much faster because the researchers split the image's information in two: low-frequency general information and detailed high-frequency information. Then, they send only the computational-friendly part of the image, which is exactly what we want to transform, the blurry, low-quality general style of the image, or in other words: the low-frequency information. Then, only fast and straightforward transformations are done on the high-frequency parts of the image to resize them and merge them with the blurry newly-stylized image, improving the results by adding details on all edges in the picture.
And voilà! You have your results with a fraction of the time and computational power needed. This is brilliant, and the code is publicly available if you would like to try it, which is always cool!
Thank you for reading!
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
References
- Liang, Jie and Zeng, Hui and Zhang, Lei, (2021), "High-Resolution Photorealistic Image Translation in Real-Time: A Laplacian Pyramid Translation Network", https://export.arxiv.org/pdf/2105.09188.pdf
- Code: https://github.com/csjliang/LPTN