Advanced Search Techniques: From Keywords to Graphs
Build a Smarter RAG System


Before we start, here is video 5/10 of the “From Beginner to Advanced LLM Developer” course by Towards AI. Join our Cyber Monday Cohort now before December 8th with 15% off here!
Check the video!
Today, we’re exploring how to improve how you find information in your RAG applications. We’ll cover everything from old-school keyword searches to more recent methods such as GraphRAG. By the end, you’ll know exactly how to make your data work for you.
Traditional Keyword Search
Let’s start simple with keyword search.
Keyword search finds exact or close matches to your search terms. It’s perfect when you know exactly what you want. If it’s there — you’ll find it.
For example, if you’re looking for company policies about “AI ethics”, keyword search will find documents with those exact words.
Two popular algorithms for keyword search are BM25 and BM42:
BM25, or “Best Matching 25”, is a ranking function used in information retrieval. It’s like a sophisticated scoring system for keyword search.
First, it looks at how often a word shows up in a document, which is called term frequency (TF). Then, it gives extra weight to words that are rarer across all documents, which is known as inverse document frequency (IDF). It also makes sure that longer documents don’t automatically get higher scores just because they have more words. Finally, it recognizes that just because a word appears a lot, it doesn’t make it drastically more important, thanks to a smart saturation function. This saturation function makes sure that after a certain point, like having 100 times the same word, these additional occurrences of the word add less and less weight to its relevance score. This helps in balancing the influence of frequently occurring words, ensuring that they don’t unfairly dominate the scoring process since a word appearing 100 times isn’t necessarily 10 times more relevant than if it appears 10 times.
BM25 balances all these factors to give you relevant results without being fooled by keyword stuffing or document length.
There’s also BM42, an evolution of BM25, specifically designed to handle longer documents and more complex queries. It introduces several key improvements. First, it uses a different saturation function that’s better suited for very lengthy documents. It also has a more effective method for dealing with query terms that don’t appear in a document. Instead of simply penalizing the document, BM42 considers other factors, like the overall context or related terms, to better assess the document’s relevance. Lastly, it introduces a length normalization component that’s more adaptable across various types of content.
So BM42 basically aims to maintain BM25’s strengths while addressing its weaknesses, particularly for modern web-scale document collections where document lengths can vary drastically.
Both these methods help make keyword search more nuanced and effective, going beyond simple word counting to deliver more relevant results.
In general, keyword search works best when you need quick, exact results. It’s great for well-organized data and specific terms. But it has limits. If the words don’t match exactly, it might miss related ideas. If we come back to our “AI ethics” example, a text referring to AI ethics as something like “ethical considerations in machine learning,” a keyword search won’t find it. That’s where we need something smarter.
Embedding Search
Ideally, we’d like a search that could understand what we mean, not just the exact same words we say.
That’s what embedding search does.
Embedding search, or semantic search or vector search, transforms both the query, like our « AI ethics » past query, and documents into high-dimensional vectors, which we call embeddings. These embeddings do more than just representing the words we have, thanks to the model’s training, they have learned capture the semantic meaning of the text. They can simply be seen as a huge list of characteristics with a value for each of them, which tells if, for example, it’s an object, its color, its shape, and etc. It can then use these new representations of words to compare them mathematically.
The search process involves computing the similarity between the query embedding, so our user question or the term we want to search, and document embeddings, which would be our dataset that we transformed into these embedding format. It typically calculates this similarity using a metric called cosine similarity. It just means that it compares each value of our query embedding vector with the other of an embedding vector from the database. It then repeats this for all embedding we have in the data to find the most relevant matches. This approach allows the system to find relevant documents based on conceptual similarity, even when exact keywords don’t match. It excels at understanding context, synonyms, and related concepts, but requires more computational resources and sophisticated models.
We use embedding search when we need to find similar ideas, even if they use different words. It’s great for research tools where people might describe the same thing in different ways. For instance, it could help find papers about “AI ethics” even if a user says “étique de l’intelligence artificielle” in French instead. Because it understands that both mean somewhat the same thing even if it’s not the same words or even language.
Hybrid Search: The Best of Both
But we don’t need to choose between keywords and embeddings. We can simply use both! That’s what hybrid search does. It combines the exactness of keywords with the captured meaning of embeddings.
It can leverage both what you say and what you mean.

Hybrid search is perfect when you need both exact matches and related content. It’s great for mixed data and when you want to balance finding everything relevant (which would be a lot of information) with finding the most relevant things, like the top 3.
For example, in online shopping, hybrid search can help customers find products even if they don’t know the exact name. At the same time, it can still find exact matches for product codes. Likewise, for our « AI Ethics » example, if the user types something like « ethical considerations of autonomous vehicles », you will find exactly the information about autonomous vehicles but also would be able to find some broader concerns related to AI and vehicles that might be relevant. Balanced right, it’s the best of both world.
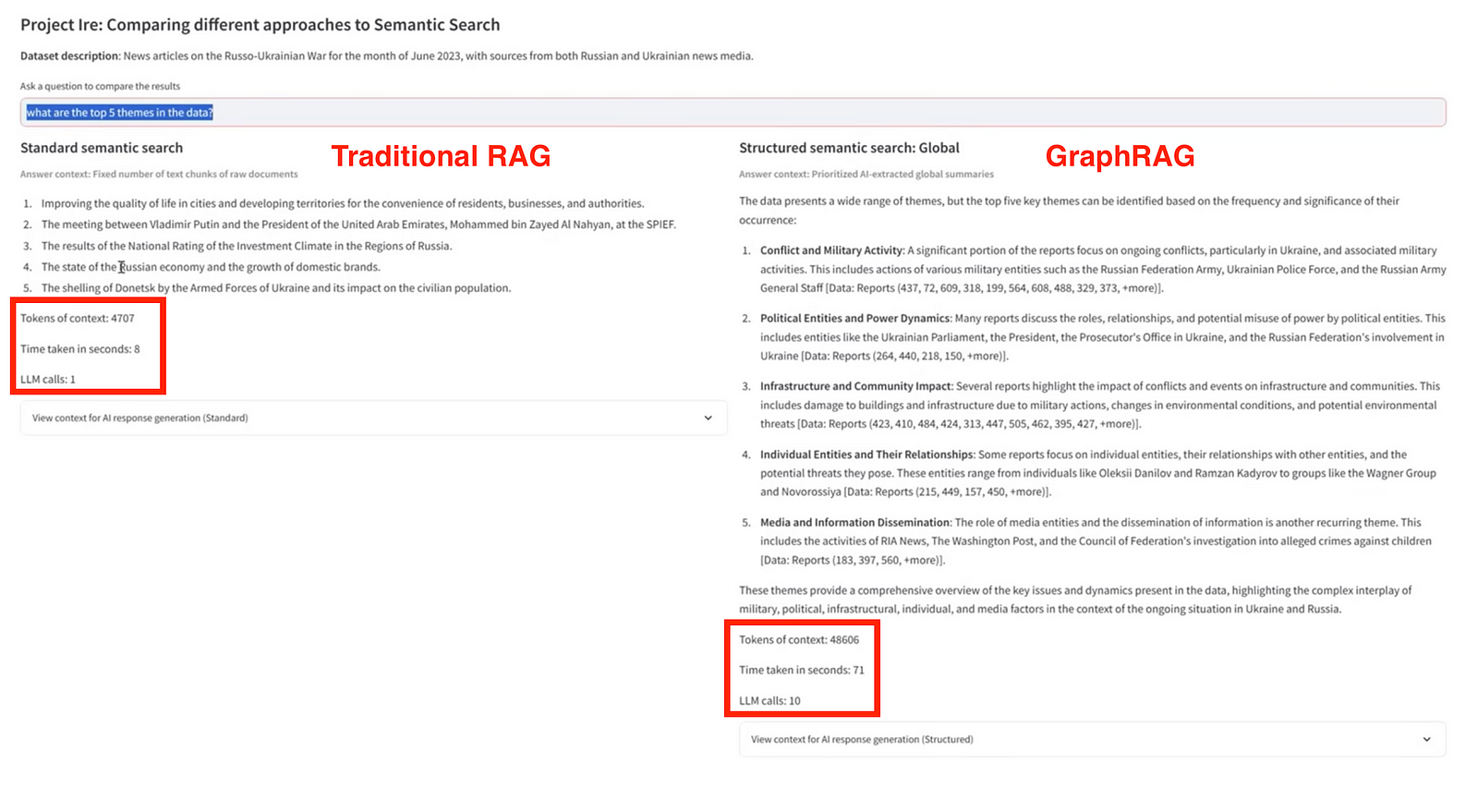
GraphRAG: Connecting Ideas
Now, let’s level up with GraphRAG, a new method popularized by Microsoft. This isn’t just about finding information; it’s about understanding how it’s all connected.
GraphRAG uses relations between objects or people, which we call knowledge graphs instead of just finding relevant documents; it discerns their relationships and extracts entities and relationships, creating a structured representation that captures semantic connections from the data.
Just to make sure we are on the same page, a knowledge graph is just a structured representation of data that captures entities and their relationships, allowing for better understanding and retrieval of information.
We use GraphRAG when the data has complex connections. It’s great for answering tricky questions that involve multiple pieces of information. Think of legal research, where you need to understand how different cases and laws connect.
But be careful: GraphRAG is powerful but slow. Currently, it can take up to 10 times longer than simpler methods, as measured by a recent Microsoft Blog Post. Make sure you really need it before you use it!
Metadata Filtering: Using Extra Info
Sometimes, the key to finding what you need isn’t in the main text, but in the extra information about it. That’s metadata filtering.
Metadata filtering lets you narrow down your search using things like dates, authors, or file types. It’s basically about using labels to organize your files.
Use metadata filtering when you need to search within specific limits. It’s great when your data has clear labels or when you want to give users more control over their search.
For example, if we have a large dataset about AI in general and we have numerous tags for each texts in there like rag, LLMs, autonomous vehicles or ethics, we’d then be able to directly get all text related to ethics without any heavy search. Just apply one filter and that’s it. We can then proceed to search in a much smaller part of our data with embedding search to find the most relevant information from this filtered subset.
The Router: Your Search Traffic Director
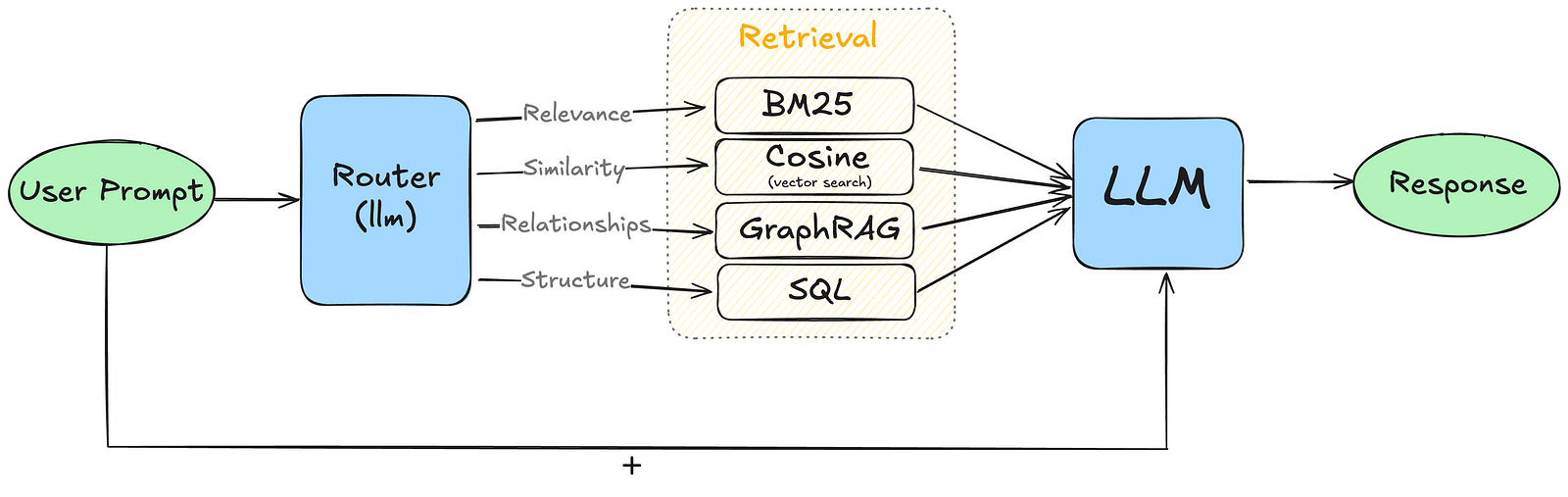
But then, with all these search techniques, how do you know which one to use? Can you just use one? Or use all of them? That’s where a router comes in.
A router chooses the best search method based on what you’re asking and what kind of data you have. It’s usually a powerful language model that understands your query and the search options you have and figures out the techniques that would best fit your needs. It would just be like you after reading this article, having a good idea of why one would use keyword search, embedding search or graphs!
Routers make your searches faster and more accurate. They can use different techniques for different questions, all in one system.
For instance, a router in a customer help system might use keyword search for product codes, embedding search for general questions, and GraphRAG for complex problem-solving.
Wrapping Up: Picking Your Search Strategy
So, which search technique should you use? Well, it depends on what you need.
For simple, organized data, stick with keyword search or with an existing SQL database. If you need to understand meaning and context, go for embedding search. Want a bit of both? Try hybrid search. Dealing with complex, connected information? Consider GraphRAG. Need to filter results? Use metadata filtering. And if you want a system that can do it all, set up a router.
Remember, the best search strategy fits your data, your users, and what your system can handle. Don’t be afraid to mix and match to create the best search for your use-case.
As you build your next data project, think about how people will look for information. The right search technique can turn a frustrating experience into a truly smart system.
If this article was useful consider taking a look at our course where we dive into RAG from zero to hero with all these filtering and search techniques and more advanced approaches for improving LLMs in real-world applications.