Realistic Lighting on Different Backgrounds
Properly relight any portrait based on the lighting of the new background you add.


Have you ever wanted to change the background of a picture but have it look realistic? If you’ve already tried that, you already know that it isn’t simple. You can’t just take a picture of yourself in your home and change the background for a beach. It just looks bad and not realistic. Anyone will just say “that’s photoshopped” in a second. For movies and professional videos, you need the perfect lighting and artists to reproduce a high-quality image, and that’s super expensive. There’s no way you can do that with your own pictures. Or can you?

Well, this is what Google Research is trying to achieve with this new paper called Total Relighting. The goal is to properly relight any portrait based on the lighting of the new background you add. This task is called “Portrait relighting and background replacement”, which, as its name says, has two very complicated sub-tasks:
- Background replacement, meaning that you will need to accurately remove the current image’s background to only have your portrait.
- Portrait relighting, where you will adapt your portrait based on the lighting in the new background’s scene.
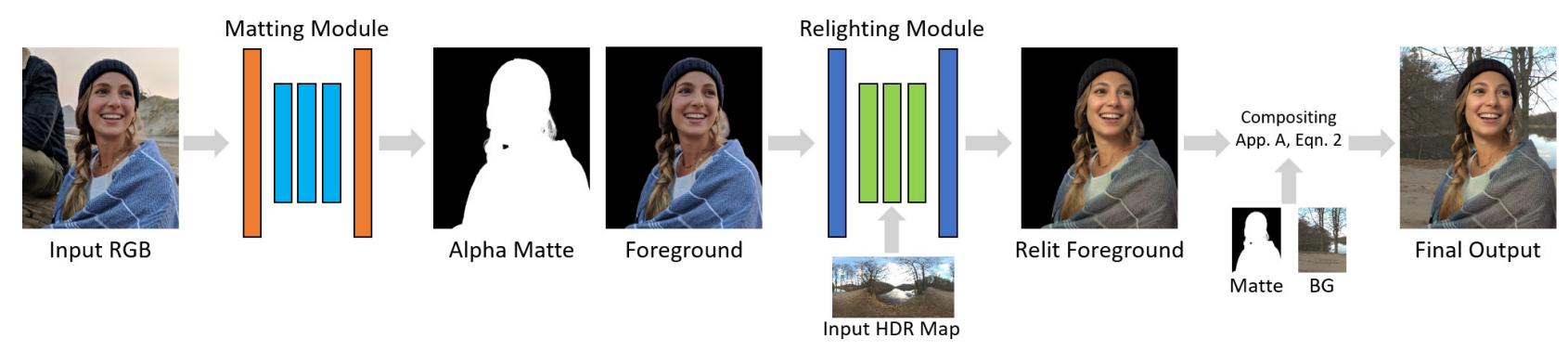
As you may expect, both these tasks are extremely challenging as the algorithm needs to understand the image to properly remove you out of it and then understand the other image enough to change the lighting of your portrait to make it fit the new scene. The most impressive thing about this paper is that these two tasks are made without any priors. Meaning that they do not need any other information than two pictures: your portrait and the new background to create this new realistic image. Let’s get back to how they attacked these two tasks in detail:
Human Matting
This first task of removing the background of your portrait is called image matting, or in this case, human matting, where we want to identify a human in a picture accurately. The ‘accurate’ part makes it complex because of many fine-grain details like the floating hair humans have. You can’t just crop out the face without the hair. It will just look wrong. To achieve this, they need to train a model that can first find the human, then predict an approximate result where we specify what we are sure is part of the person, what is part of the background, and what is unsure.


This is called a trimap, and it is found using a classic segmentation system trained to do exactly that: segment people in images. This trimap is then refined using an encoder-decoder architecture, as I already explained in a previous video if you are interested. It basically takes this initial trimap, downscale it into condensed information, and uses this condensed information to upscale this into a better trimap.
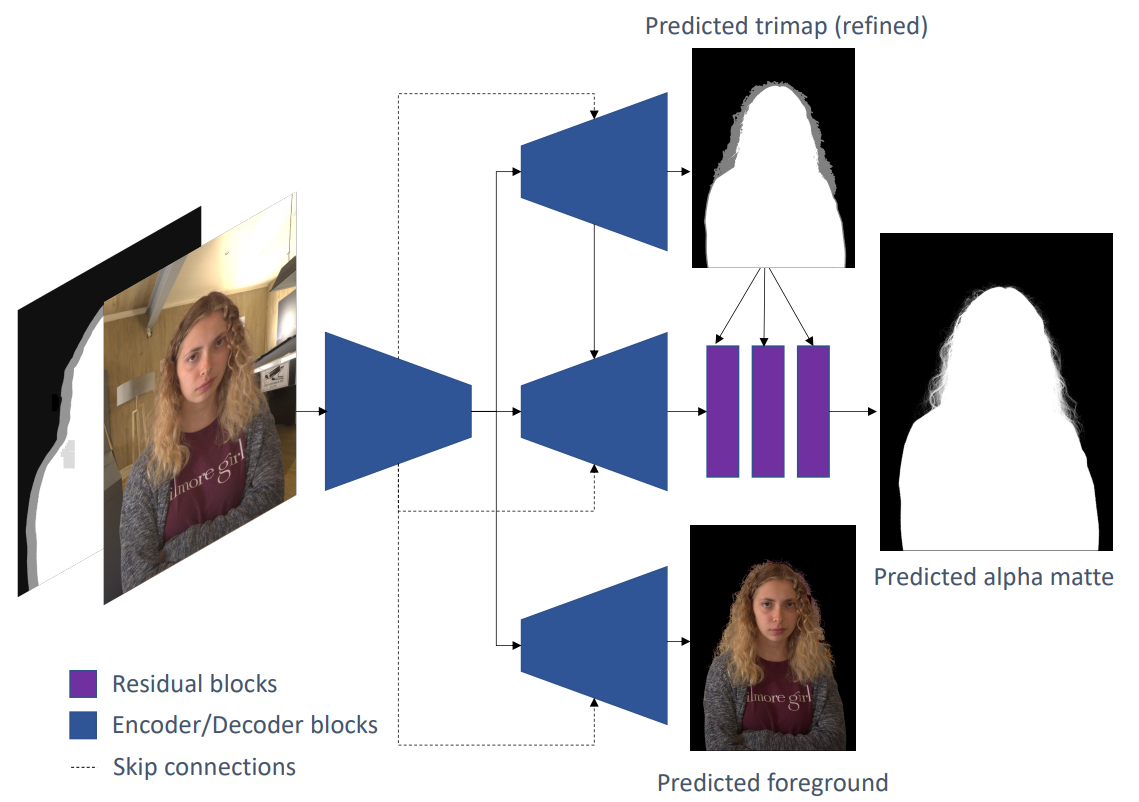
This may seem like magic, but it works because the network transforming this trimap into code and code into a better trimap was trained on thousands of examples and learned how to achieve this. Then, they use this second trimap to again refine it into the final predicted human shape, which is called an alpha matte. This step also uses a neural network. So we basically have three networks involved here, one that takes the image and generates a trimap, a second that takes this image and trimap to improve the trimap, and the last one that takes all these as inputs to generate the final alpha matte. All these sub-steps are learned during training, where we show many examples of what we want to the networks working together to improve the final result iteratively. Again, it is very similar to what I previously covered in my video about MODNet, a network doing precisely that, if you want more information about human matting.
Here, all these networks composed only the first step of this algorithm: the human matting. What’s new with this paper is the second real step, which they refer to as the relighting module.
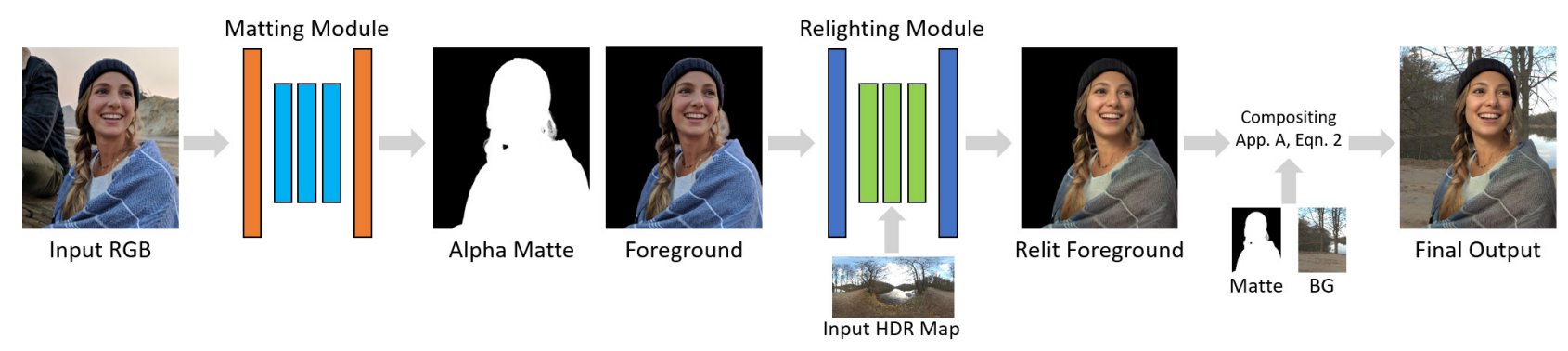
Relighting Module
Now that we have an accurate prediction of where the person is in the image, we need to make it look realistic. To do so, it is very important that the lighting on the person matches the background, so they need to either relight the person or the background scene. Here, as most would agree, the simplest is to relight the person, so they aimed for this. This relighting was definitely the most complex task between the two as they needed to understand how the human body reacts to light.

As you can see here, there are multiple networks here again. The geometry net, an albedo net, and a shading net. The geometry net takes the input foreground we produced on the previous step to produce surface normals. This is a modelization of the person’s surface so that the model can understand the depths and light interactions. Then, this surface normal is coupled with the same foreground image and sent into an albedo net that produces the albedo image. This albedo image is simply a measure of the proportion of light reflected by our object of interest, which is a person, in this case, reacting to light from different sources. It tells us how the clothing and skin of the person react to the light it receives, helping us for the next step. This next step has to do with the light of the new background. We will try to understand how the new background lighting affects our portrait using learned specular reflectance and diffuse light representations of our portrait here called light maps.

These light maps are calculated using a panoramic view of your wanted background. Just like the name says, these light maps basically show how the light interacts with the subject in many situations. These maps allow us to make the skin and clothing appear shinier or more matte depending on the background’s lighting. Then, these light maps, the albedo image, and the foreground are merged into the final and third network, the shading network.

This shading network first produces a final version of the specular light map using the albedo information coupled with all the specular light map candidates we calculated previously. Using this final light map, our diffuse map, and the albedo, we can finally render the final relit person ready to be inserted on our new background.
As you saw, all the networks looked the same, exactly like this, which is called a U-Net, or encoder-decoder architecture. Just like I already said, it takes an input, condenses it into codes representing this input, and upscale it into a new image. But as I already explained in previous videos, these ‘encoder-decoders’ just take an image into the first part of the network, which is the encoder that transforms it into condensed information called latent code that you can see here on the right. This information basically contains the relevant information to reconstruct the image based on whatever style we want it to have. Using what they learned during training, the decoder does the reverse step using this information to produce a new image with this new style. This style can be a new lighting orientation, but also a completely different image like a surface map or even an alpha matte, just like in our first step.
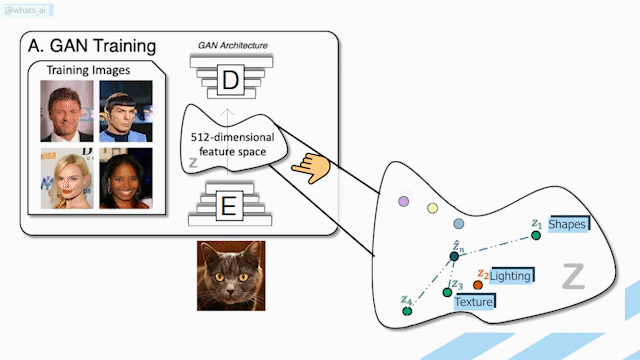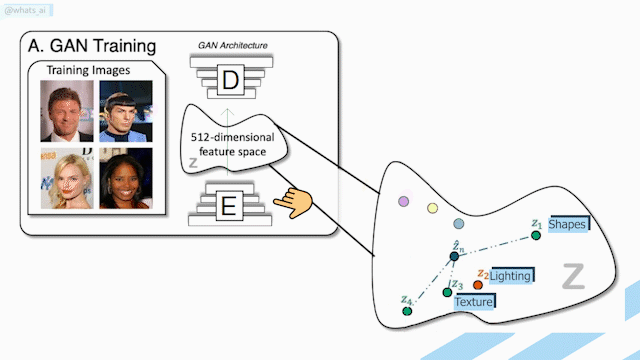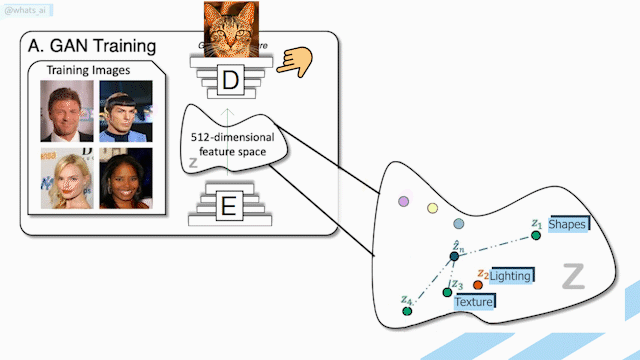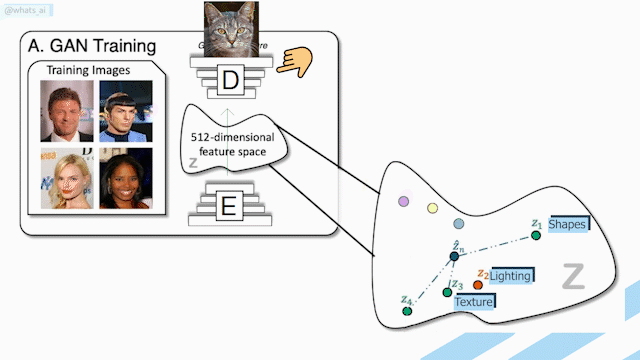
This technique is extremely powerful, mainly because of the training they did. Here, they used 58 cameras with multiple lights and 70 different individuals doing various poses and expressions. But don’t worry, this is only needed for training the algorithm. The only thing needed at inference time is your picture and your new background. Also, you may recall that I mentioned a panoramic view was needed to produce this re-lightened image, but it can also be accurately approximated with another neural network based on only the background picture you want your portrait to be translated on.
And that’s it! Merging these two techniques together makes it, so you just have to give two images to the algorithm, and it will do everything for you, producing a realistically re-lightened portrait of yourself with a different background! This paper by Pandey et al. applies it to humans, but you can imagine how useful it could be on objects as well where you can just take pictures of objects and put them in a new scene with the correct lighting to make them look real.
Watch the video
Thank you for Reading!
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
References
Pandey et al., 2021, Total Relighting: Learning to Relight Portraits for Background Replacement, doi: 10.1145/3450626.3459872
Paper: https://augmentedperception.github.io/total_relighting/total_relighting_paper.pdf
Project link: https://augmentedperception.github.io/total_relighting/