CAG vs RAG: Which One is Right for You?
Is CAG the Future of LLMs?

Watch the video!
If you’re using ChatGPT or other AI models, you’ve probably noticed they sometimes give incorrect information or hallucinate. RAG helps solve this by searching through external documents, but this new approach takes a completely different approach — and it might just be what you need!
Good morning everyone! This is Louis-Francois, co-founder and CTO at Towards AI, and today, we’ll dive deep into something really exciting: Cache-Augmented Generation, or CAG.
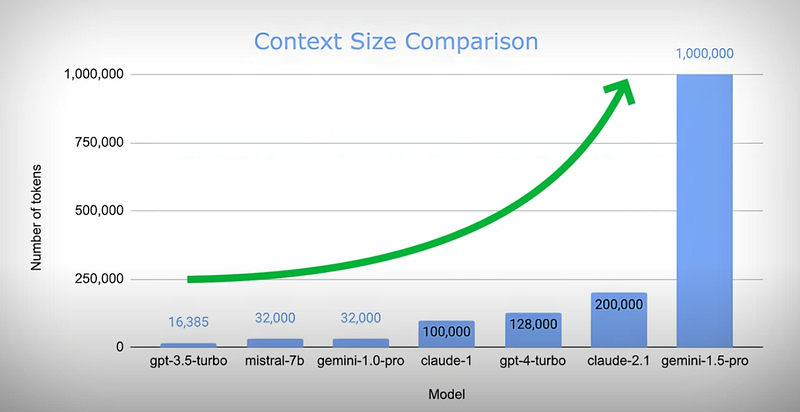
In the early days of LLMs, context windows, which is what we send them as text, were small, often capped at just 4,000 tokens (or 3,000 words), making it impossible to load all relevant context. This limitation gave rise to approaches like Retrieval-Augmented Generation (RAG) in 2023, which dynamically fetches the necessary context. As LLMs evolved to support much larger context windows — up to 100k or even millions of tokens — new approaches like caching, or CAG, began to emerge, offering a true alternative to RAG. Why did it take so long to begin? While CAG is efficient, it does come with costs. Back when GPT-4 first launched, using these large context models was up to 20x more expensive compared to today’s models, or even hundreds of times more expensive with the current mini models. These early challenges reinforced the dominance of RAG for many use cases. However, we will see why these recent improvements in model efficiency and cost have made CAG a much more viable alternative.
So, what is CAG? When using language models, there’s usually a tradeoff between speed and accuracy. RAG is great for accuracy but needs time to search through and compare documents. And it gets worse the more data you have. This is where CAG comes in and says, “What if we just preloaded all that knowledge directly into the model’s memory?” Just like in long-context models like Gemini, where you can send millions of words in a single query. But CAG makes this even more interesting.
We hear about LLMs, prompts, and RAG everywhere, but CAG is becoming just as important, especially for applications where speed really matters. I recently talked with developers in our Learn AI Together Discord community, and almost everyone wants to implement CAG in their applications.
Let’s quickly clarify how CAG works to then better understand when we should use it. CAG uses something called a Key-Value (or KV) cache. In regular LLMs, when they process text, they create these KV pairs — think of Keys as labels and Values as the actual information. The language model then works with keys and values to understand the content and generate its response. Usually, these are temporary and disappear after each response. But CAG says, “Hey, why not save these and reuse them?” Yes, CAG is used to save ALL your information in the cache of the model. Well, more specifically, it saves your computations from text to the intermediate results the transformer model sees, which is still quite a lot of computation saved if you are sending the same long context for every query. While this saves time processing all the text into these two K and V pairs, we bring more compute to the table filling in the context size with the whole dataset we have.
While there are several reasons why CAG is gaining popularity, it’s mostly because of three things:
- It’s fast — no need to search through documents anymore.
- It’s more reliable — no risk of retrieval errors, but there’s a risk of adding irrelevant information to every queryà, often causing issues to LLMs not being able to find the valuable information in it.
- It’s quite simple — You don’t need a complicated search-and-retrieval pipeline — just the LLM and its preloaded cache.
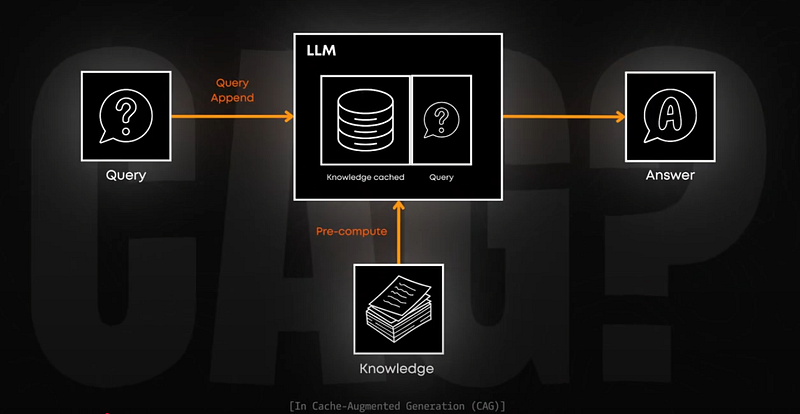
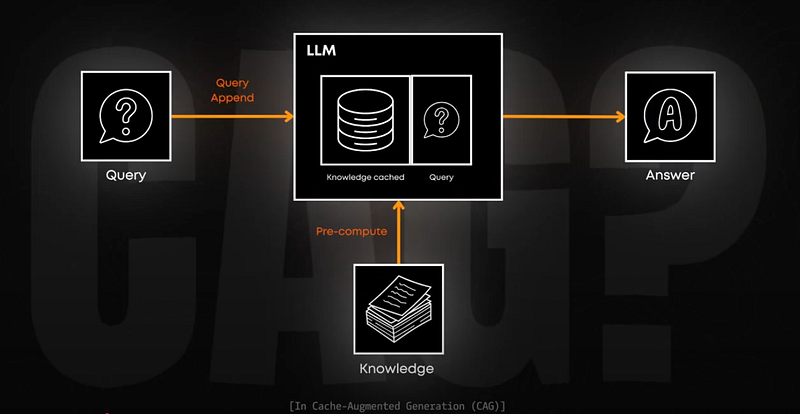
Put simply: instead of searching through a database every time (like RAG does), CAG preloads all the information into the model’s memory. All of it. Here’s what happens in a CAG-based system: you preload knowledge into the KV cache -> user question -> direct access to cached knowledge -> instant answer.
As you can see, with CAG, we completely eliminate the search step. This makes responses super fast and more reliable since we’re not depending on a search algorithm to find the right information. But there are some important downsides.
- You’re limited by your model’s context window — currently around 128,000 tokens (about 100,000 words) for most. This means you can’t simply load your huge dataset of millions of rows directly and have instant, reliable answers. It doesn’t work like that.
- It is super efficient, but costlier as you are still sending a lot of context every time to the LLM, even for simpler queries, whereas RAG sends just the necessary bits.
- You can get issues with sending too much information and not finding the relevant bits. An important challenge to consider with CAG is the ‘lost-in-the-middle’ problem: even with large context windows, LLMs often struggle to retrieve specific content distributed across multiple parts of the input, whereas RAG is used to pinpoint only the required information.
Speaking millions of words, Google has something very similar in their Gemini API — they call it “context caching.” It’s essentially the same principle: you load your content once, cache it, and reuse it for subsequent requests. It makes it more efficient since you use fewer tokens. CAG is not that new and has been around for some time!
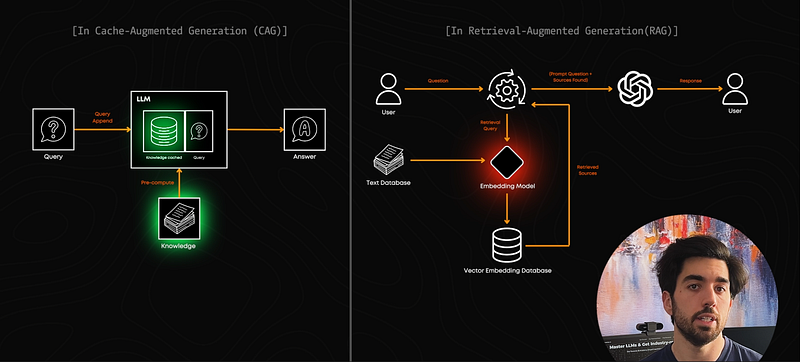
If you’re a more technical viewer and want to understand the whole process, here’s a small bit for you: To build a CAG-based system, you start by preprocessing your entire knowledge base. Instead of creating embeddings like in RAG, you’re generating and saving the model’s internal representations (the KV cache) of your data. This is done through a process called KV-Encode in the original paper, which transforms your text into a format the model can instantly access.
Then, when a question comes in, the model directly uses this cached knowledge to answer the question with precision! You can also efficiently reset or update this cache whenever needed.
Just note that here, in most cases, this is implemented by the LLM provider unless you host it yourself. As a user, you’ll simply set a variable related to using cache to true, and they will manage the rest.
Just like in our RAG discussion about embeddings, CAG also has its own optimization techniques. For example, you might need to handle cache management, implement efficient truncation strategies, or deal with position ID rearrangement.
To make it a bit more simple, here are straightforward rules to know when you should consider it:
- When your knowledge base fits within the model’s context window
- When you need extremely fast responses
- When your information doesn’t change frequently
- When increased overall costs are ok for your use case
- When you don’t see relevant decreases in output quality with respect to RAG
- If you are hosting the model, consider CAG when you have sufficient GPU memory (yes, that KV cache needs to live somewhere and is quite expensive in space, filling the context window!). If you are using the model through an API, forget about that one; you can just set the cache feature to True and forget it!
For example, you may want to use CAG when you have a chatbot that requires you to answer the same FAQs often so the bot always knows how to respond. Or to answer questions for a specific report or meeting recording quickly, such as creating a YouTube “chat with your videos” type of add-on.
If you want an easy analogy to make your next decision, imagine you need to do an exam, and you need to make a choice. Do you want to have access to the whole textbook where you need to find information as you go or have a perfectly memorized only chapters 6 and 7 of the textbook beforehand? Both approaches work, but they shine in different situations! RAG will be best where you need the whole book to pass the exam, whereas CAG will be ideal if the exam is on chapter 7 only!
Before some of you ask — yes, you could combine CAG with RAG in a hybrid approach. You can have your most frequently accessed information in CAG for instant access while using RAG for more rarely needed details. It’s like having both a perfect memory for your specialization and a huge library at your disposal for all facts!
As LLMs become even better at managing vast contexts with lower costs, a well-implemented context caching feature could become the default for most projects just because it’s so efficient. Still, RAG will likely remain indispensable for edge cases where knowledge bases are exceptionally large or highly dynamic.
I hope this article helped you understand what CAG is, how it differs from RAG and when to use both. If you find it helpful, please share it with your friends in the AI community, and don’t forget to follow the newsletter for more in-depth AI content!

Thank you for reading!