How to Build a Multimodal LLM like GPT-4o?
Chameleon Paper Explained


Watch the video:
These past weeks have been exciting, with the release of various revolutionary multimodal models, like GPT-4o or, even more interestingly, Meta’s open-source alternative, Chameleon.
Even though it’s a mouthful, all future models will be multimodal.
But what exactly is a multimodal model, and why is it important? My name is Louis-François. I’m one of the founders of Towards AI, where we try to make AI more accessible through free content like this video and other learning resources like our recent book. Today, we are diving into multimodal models thanks to Chameleon’s paper, which has very useful details for building such a powerful model.
Multimodal refers to handling different types of information — like audio, video, text, and images where each of it is called a mode. Hence the name multimodal, for multiple modes or modality. When a model works with just one type, like GPT-4 for text, it’s unimodal. In the case of GPT-4o, you can feed it images and audio directly without having to transform these other modalities beforehand.
To understand the entire process better, let’s take an example of describing your favorite scene in a movie to a blind person. You may need to tell them every detail, say the people, their emotions, the aesthetic, and the overall mood. For this, there needs to be a complete synchronization of the text and the scene. The visual, and the audio. The text alone won’t do it justice. The model would be able to generate this much easier, if it understood both the text and the corresponding video frames.
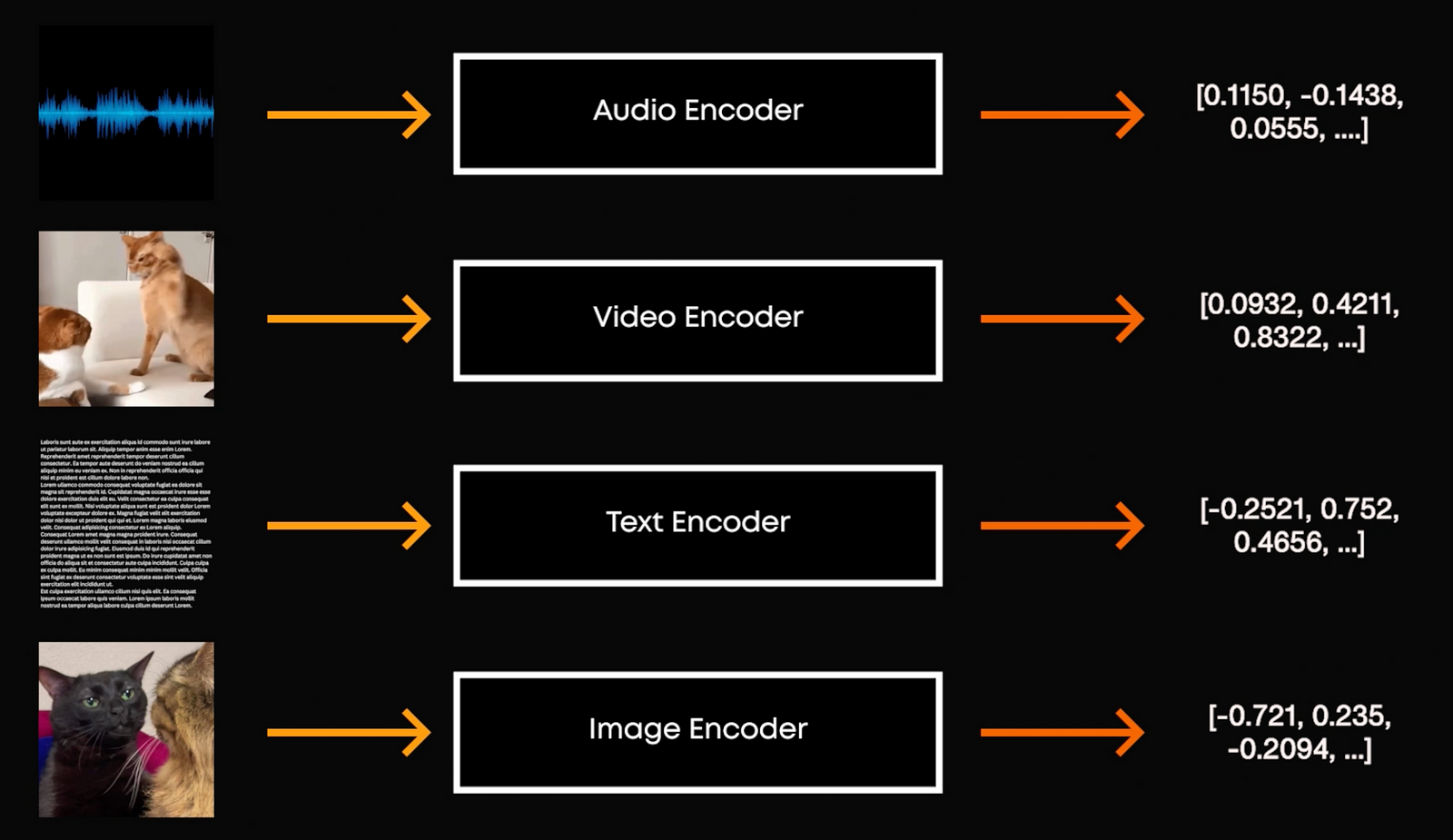
That’s where multimodal models come in handy.
But how do we do that? How can we take images, text and audio as text is much different than pixels or sound raves? Each image or text or a mode is converted into a numerical form. Now, the numerical form captures the basic details/ features in a compressed form. This is called encoding our information and is done by an encoder. So all the data that we previous had is compressed into a smaller space we call the latent space. We then process that with our model like a Transformer and generate back text using a decoder, doing the reverse and takes this context vector or simpler numerical form into the medium we desire, like a nicely formulated answer by ChatGPT.
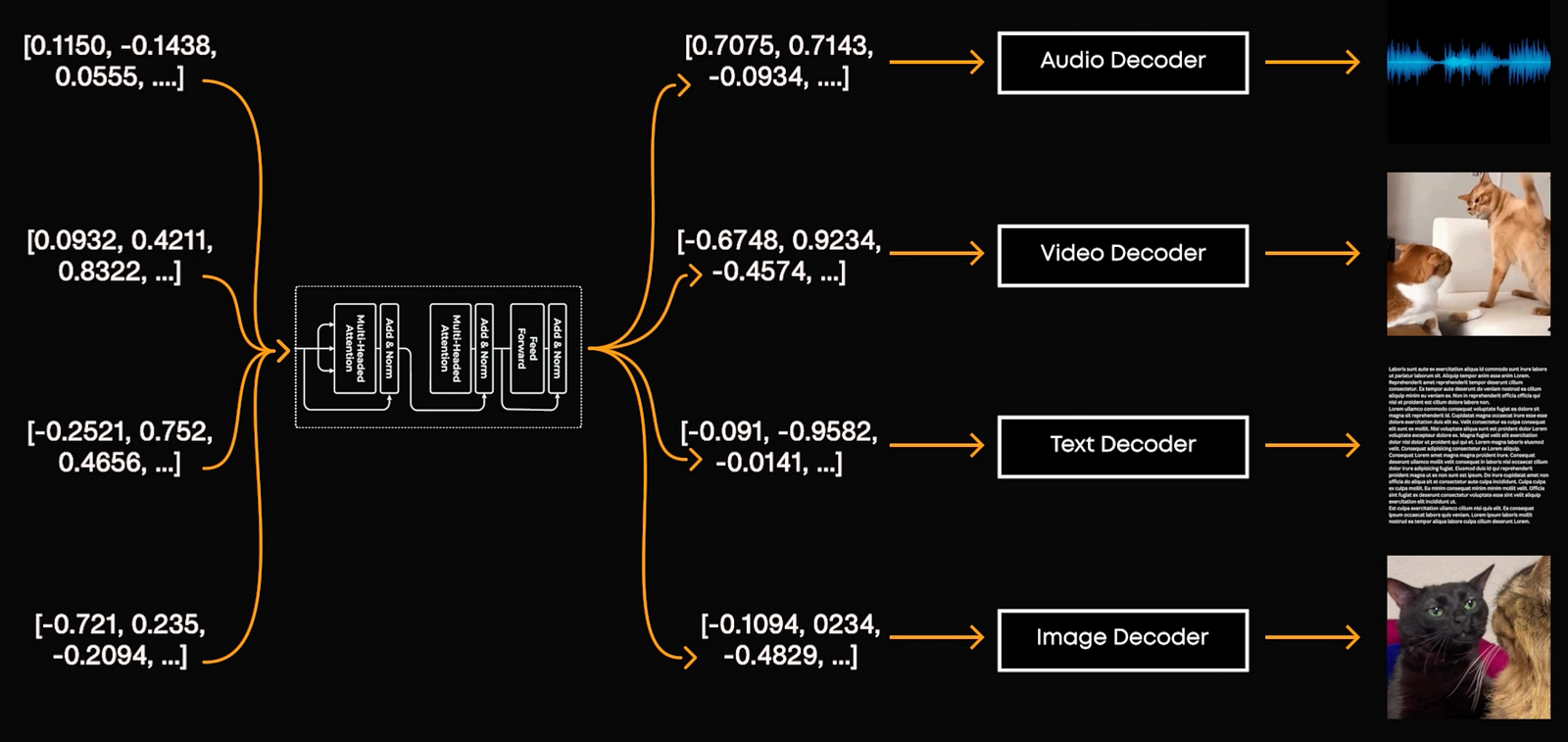
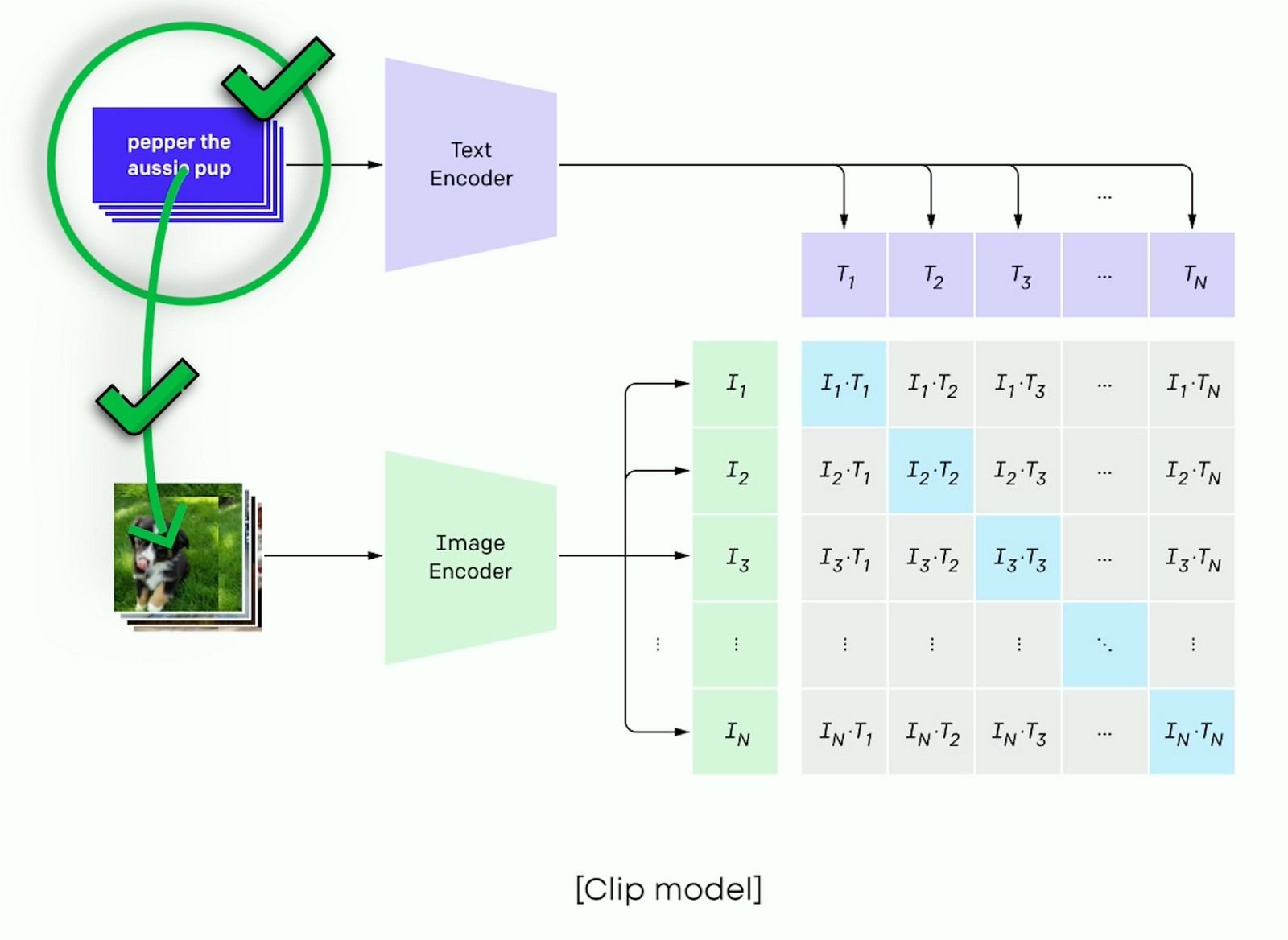
As you may think, Dall-E, MidJourney and other image generator models are multimodal models, too. They take text and images to create edited images. So what’s different? The encoding process is converting an image and the text to this encoded space separately. For encoding and decoding, they have modal-specific competent image encoders, text encoders, and learn to make similar encodings for similar concepts in both formats, for example using something like the CLIP model we talked about in a previousd video.
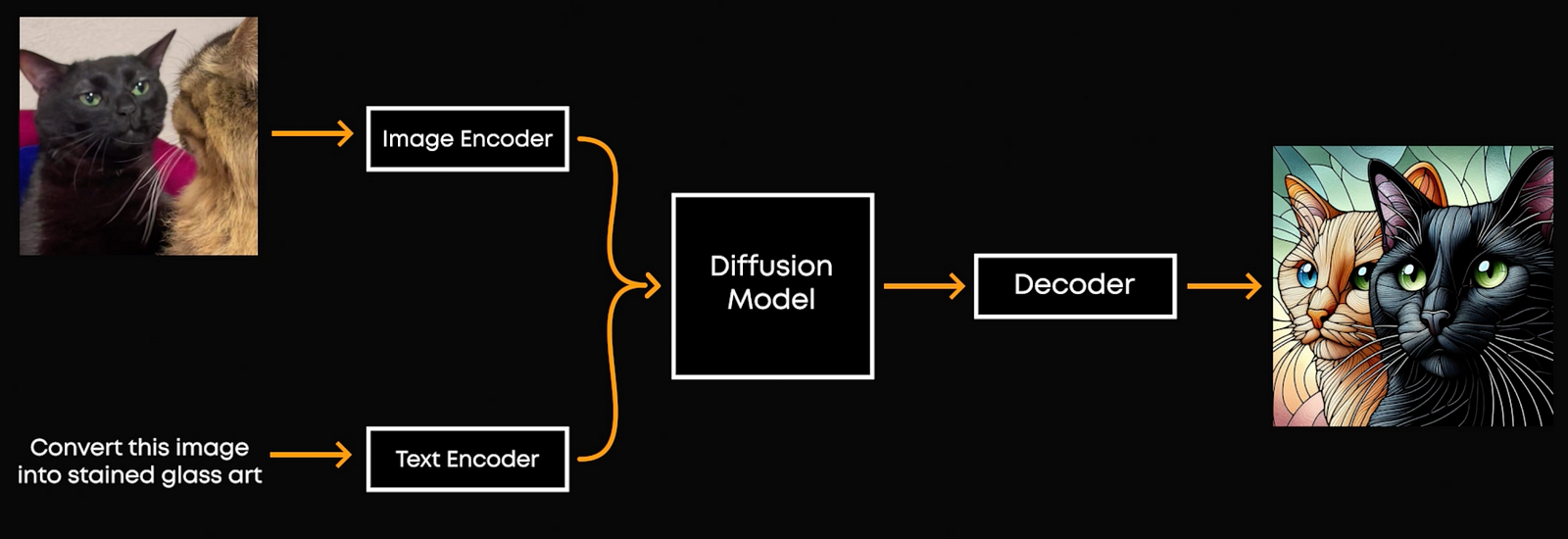
The problem is that it’s very resourceful and the image and text are always a bit different more similar to their own modality. Instead of having separate mechanisms for these, what if we combine them into one? It would make generating interleaved image and text sequences easy without specific components. Well, Gemini does exactly that, using the same encoding mechanism, regardless of whether it’s an image or text. But, while decoding or converting from the numerical form to the medium we desire, Gemini uses separate processes.
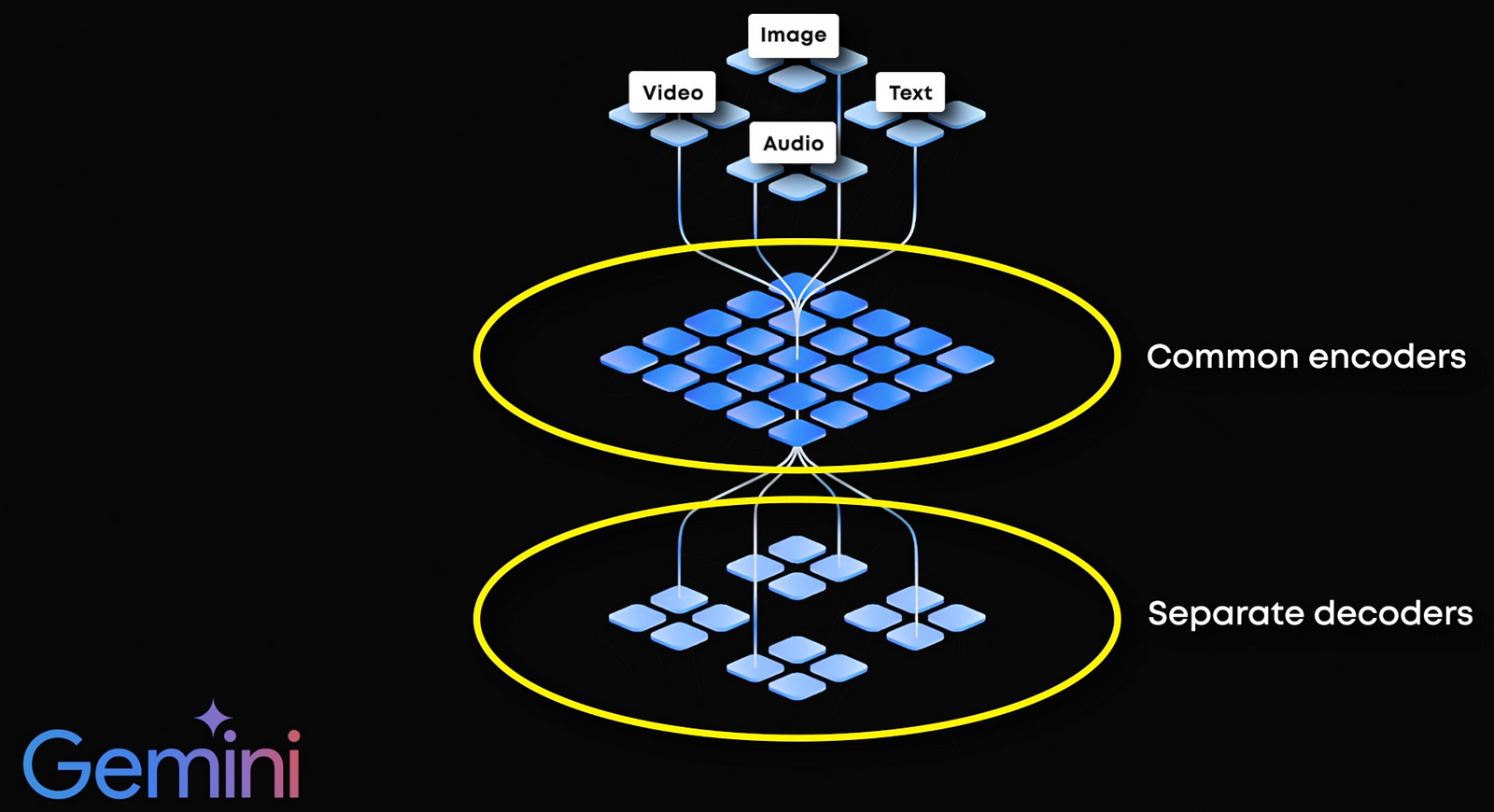
This is where the new Chameleon model by Meta differs the most. Even when decoding, it uses the same decoding mechanism. This makes it a seamless end-to-end multimodal model, which they refer to as a fusion model.
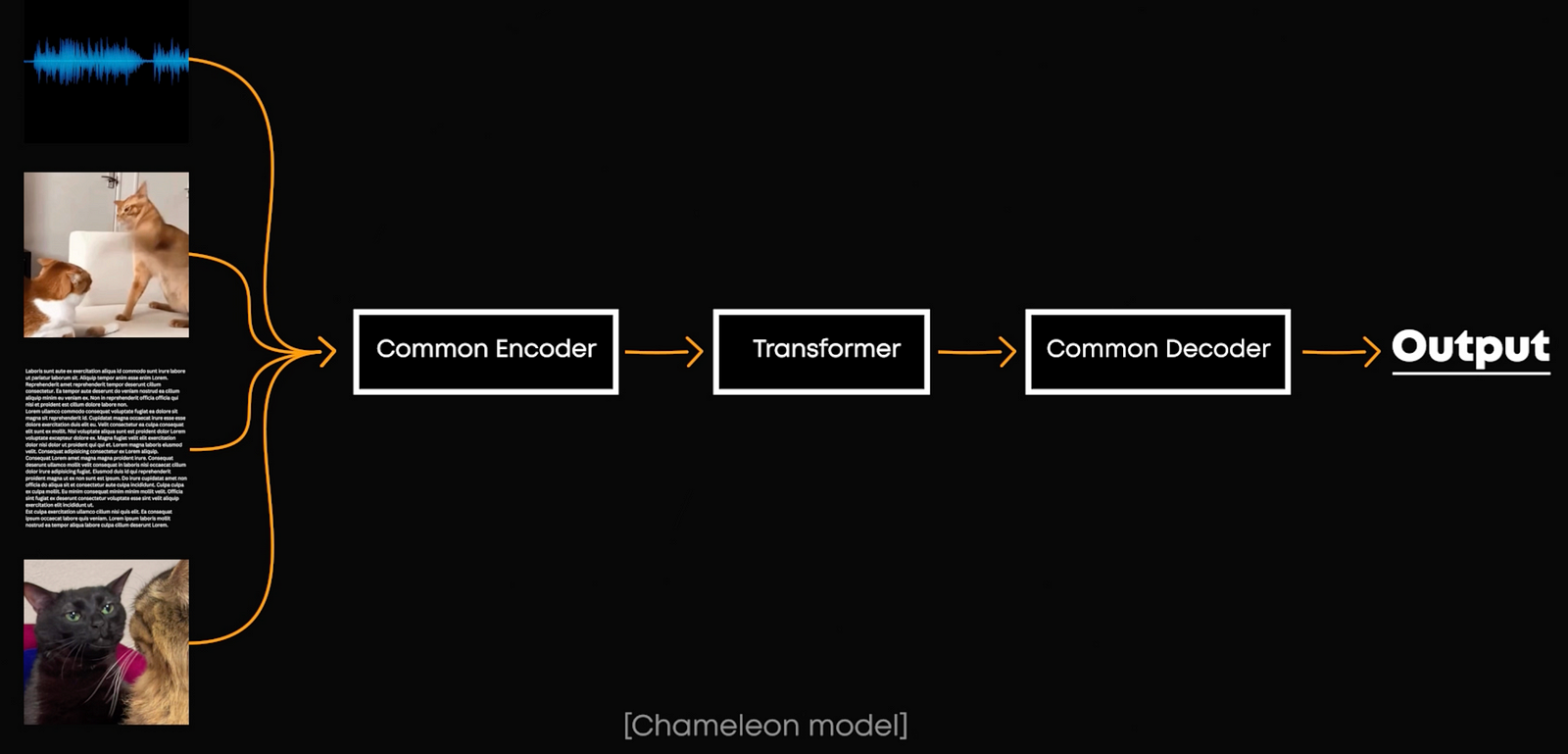
A Transformer generates one token or word at a time. For text, this is straightforward because text doesn’t need a specific length. But for images, which need specific dimensions, Chameleon restricts the token lengths for images and masks image tokens when generating text.
If it sounds so simple, why didn’t previous models use a unified encoder? It’s because implementing this is quite challenging. Remember the latent space that we previously talked about? Different data types compress differently into this space. As I said with CLIP where text often aligns more with other texts than the image it is describing, and aligning these different types properly is crucial for the model to perform well.
Take our example of describing a movie scene. The text and images must be perfectly synchronized when converted to a series of numbers. This alignment is tough. Just think of the frame rate, like which frame to take for what is being said, and some more textual descriptions or sounds happening in the scene. It becomes complicated quite fast if you want to understand everything, and can cause stability issues during training.
So, how exactly did they solve these issues? They made a few key architectural design choices to the previous transformers models based on their observations while building and training them.
During training of these multimodal models, they noticed the model’s performance degraded over time. This was due to a slow increase in certain values, or norms, caused by the softmax function. What’s a softmax function? It transforms a vector of scores into probabilities. This essential function takes our processed numbers by our transformer blocks and creates real probabilities in the range of 0 to 1, and ensures the sum of all probabilities equals to 1. However, softmax alone doesn’t address the scale of the values before it’s applied, which can cause problems over time.
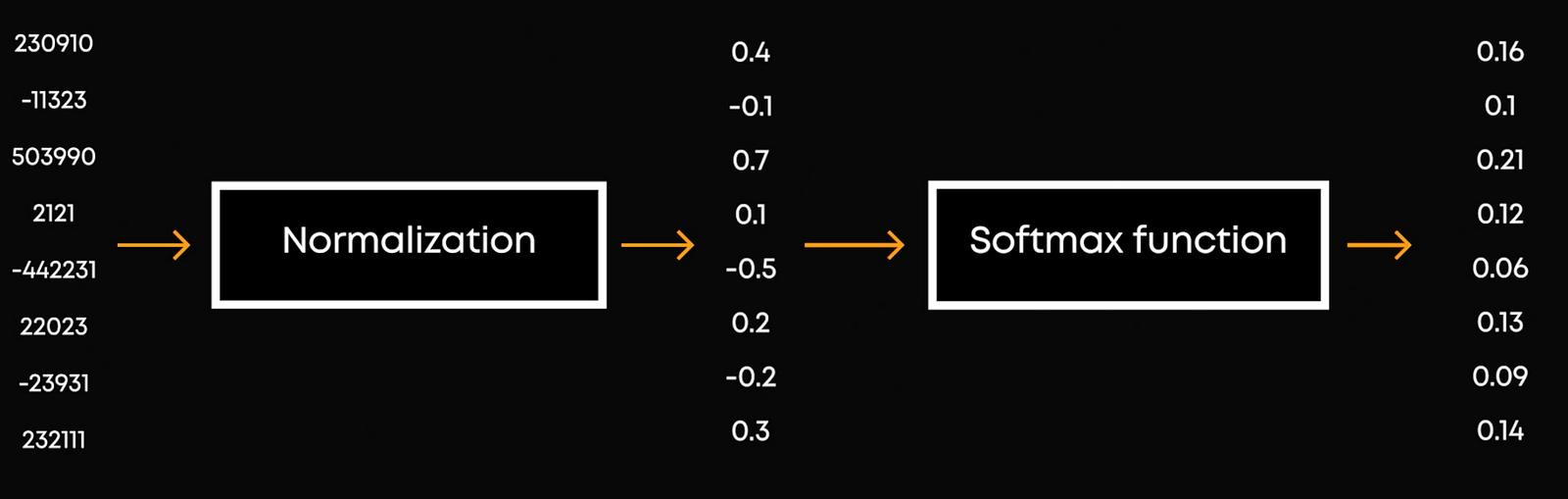
Normalization, on the other hand, ensures that the values fed into the softmax function remain stable by keeping them within a certain range. This helps in maintaining consistent training and performance. Without normalization, the values can grow too large, leading to instability.
Here’s the problem: softmax doesn’t change if you add a constant to all inputs. This means that as the model trains on millions of examples, the values can slowly grow, causing instability. This instability occurs right before the softmax functions in the attention mechanism of transformers.
This instability is caused by one particular bottleneck right before our softmax functions: the attention mechanism in transformers. In the attention mechanism, a query is like asking a specific question about the scene, such as “Who are the characters?” The keys are the pieces of information in the scene, like the details about the characters, aesthetic, and mood. The values are like the actual information about each character, such as their appearance and actions. The model uses queries and keys to calculate attention scores. These scores are then used to weight the value and their importance to that particular scene. These scores might be a huge number. Normalization ensures that the attention scores are scaled appropriately, allowing the model to weigh the importance of different inputs effectively.
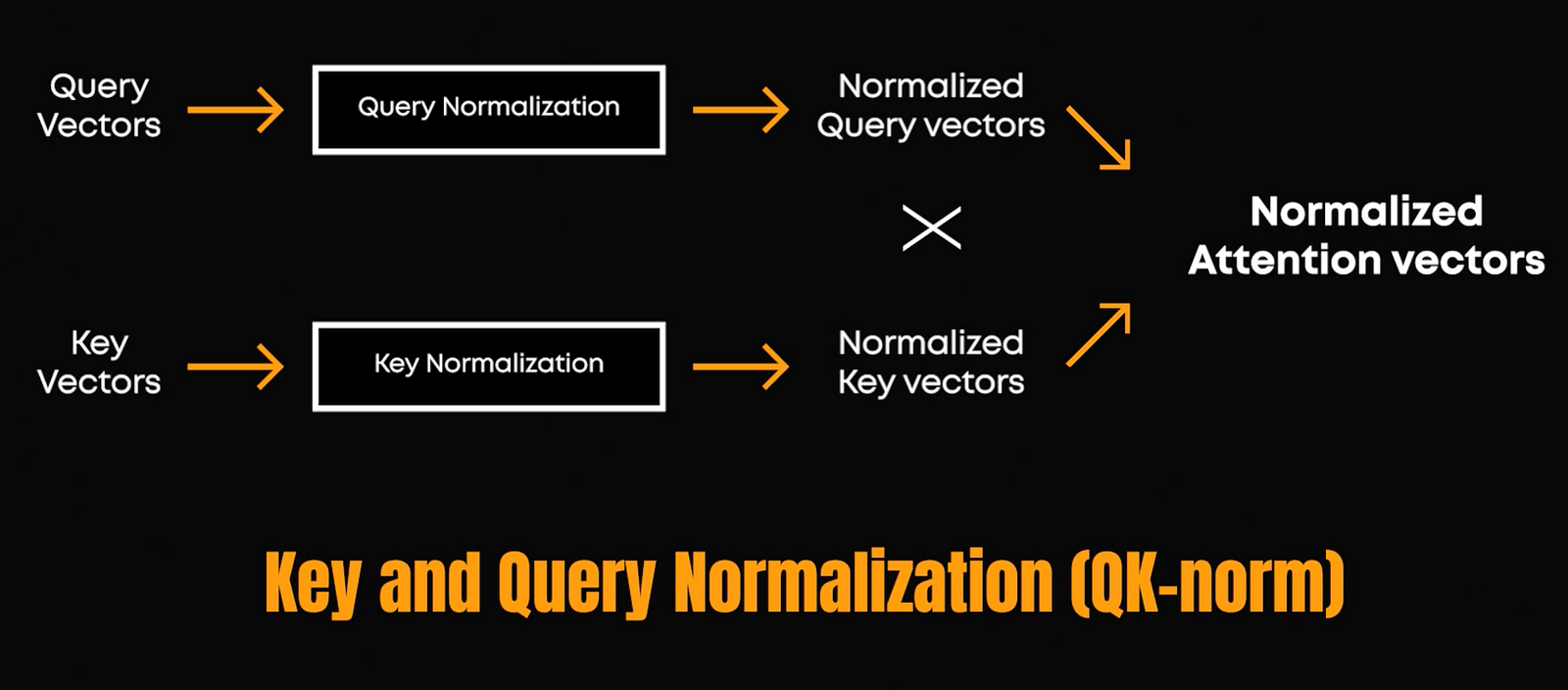
This is the process behind any transformer, but what happens here is that each medium, like image or text, competes with each other to update the values, and the growth of the values increases, causing instability. To overcome this, they’ve changed the normalization step to better control this growth of input values in the softmax function by applying layer normalization to the key and query vectors in the attention mechanism. This was the first change and is called “Key and Query Normalization (QK-norm)”.
We already saw that the normalization helps us control the growth of the input values. But in the usual transformers such as Llama, the transformer had this structure:

Here, normalization, or making the values fall within a certain range, happens after computing the attention. They’ve increased the stability of the model by changing or re-ordering the norms so that normalization occurs before these processes.
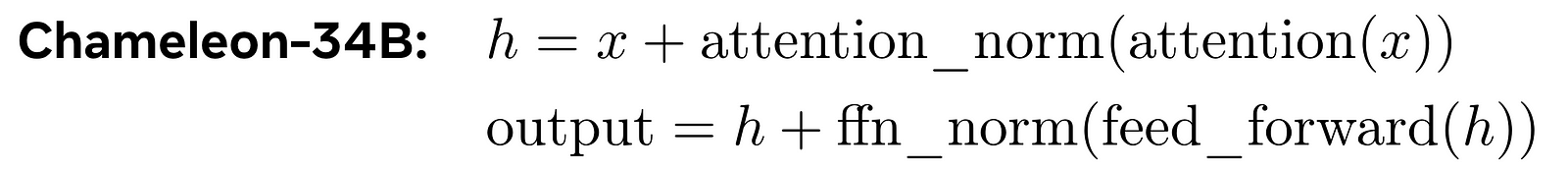
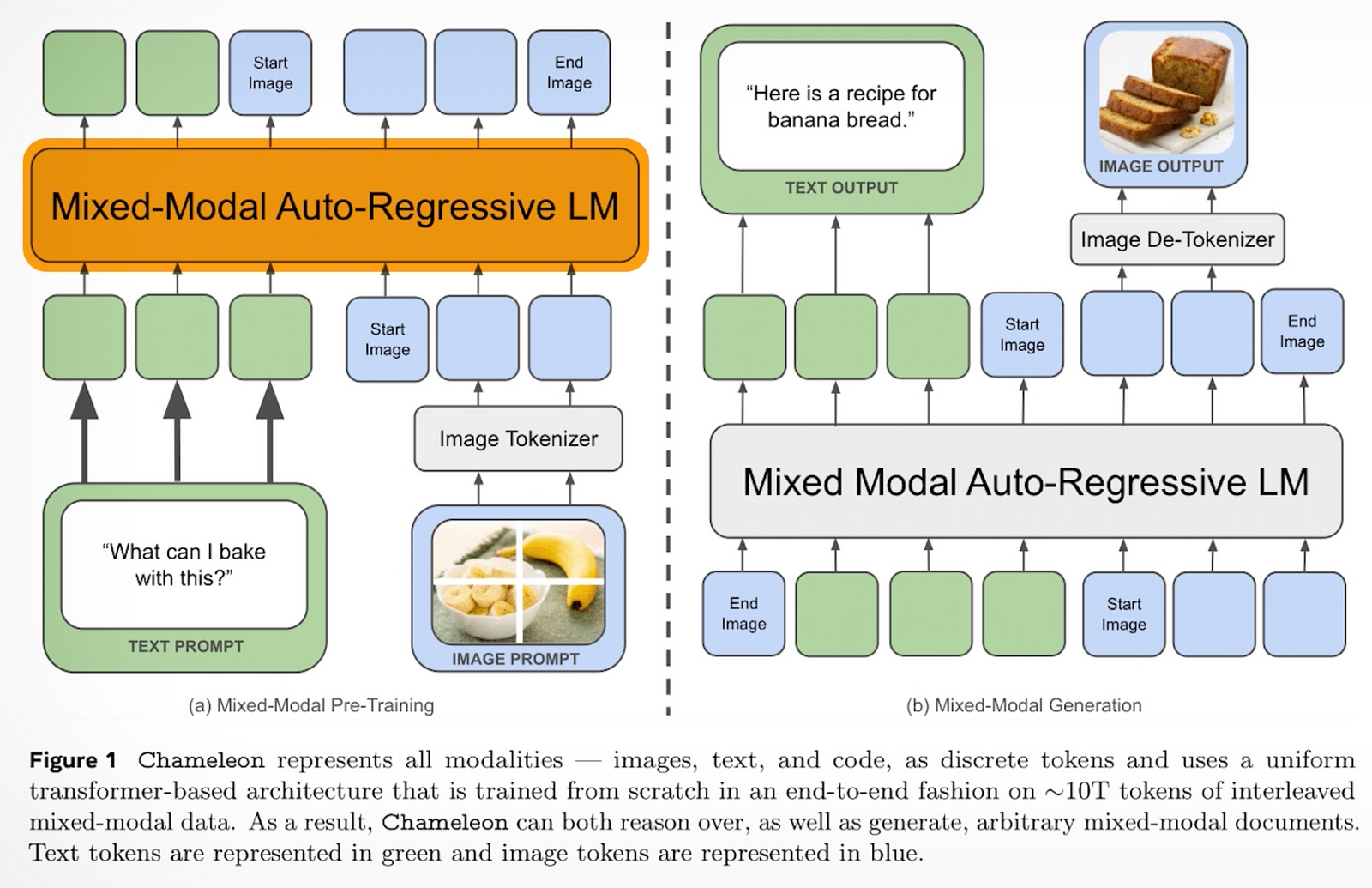
Now that we’ve looked into the “how” of building a multimodal model, where exactly is this useful and differs from other models, like GPT-4 or Llama? In applications such as answering questions about an image like this one or other application where you want to film something and ask questions, as in the recent OpenAI demo videos that made a lot of noise…

In cases where you need visual or audio information about our world and text in cohesion, these models would outshine the others. For instance, in our previous movie description example, we needed every scene detail relative to the text. Using the exact encoding representation, Chameleon handles both image and text data. It makes learning relationships between images and text more efficient by compressing all the data into the same space. Since decoding is the same representation, it is one complete process and makes reasoning better. Hence, an end-to-end model performs better for efficiency and consistency in both training and results. It’s a significant step forward in multimodal AI, combining different data types seamlessly.
If you’re interested in learning more about how large language models work, how to adapt them to your specific use cases, or how these design choices might impact you, consider reading our new book Building LLMs for Production, written by more than a dozen experts from Towards AI, LlamaIndex, Activeloop, Mila, and more. This book trains you for everything related to LLMs from prompting, fine-tuning to Retrieval-Augmented Generation (RAG) to reduce their hallucinations, make them more aligned and build powerful applications with them, covering everything from basic to advanced techniques for anyone with Python knowledge.
Thank you for reading the whole article. I will see you in the next one with more AI explained!