What is ChatGPT?
OpenAI's most recent conversational AI explained


Watch the video
ChatGPT has taken on Twitter and pretty much the whole internet, thanks to its power and the meme potential it provides. We all know how being able to generate memes is the best way to conquer the internet, and so it worked.

Since you’ve seen numerous examples, you might already know that ChatGPT is an AI recently released to the public by OpenAI, allowing you to chat with it. It is also called a chatbot, meaning you can interact with it conversationally, imitatting a one-on-one human discussion.
What you might not know is what it is and how it works.
ChatGPT is a model based on reinforcement learning and the GPT series of models from OpenAI. I will refer you to a video about reinforcement learning we recently published with my friend Elias to learn more about this subfield of AI, but quickly, reinforcement learning is a way to train algorithms by trial and error aiming for rewards, just like humans would learn with positive feedback.
More specifically, ChatGPT was built following three steps.
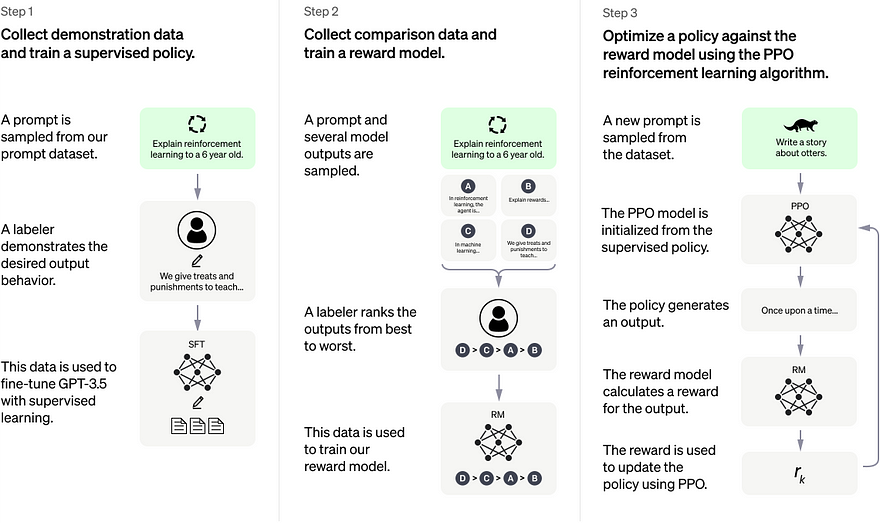
The first was to take an already powerful model and fine-tune it with supervised learning. What does this mean? It means that they took a model, specifically, it is GPT-3.5, an improved and up-to-date version of GPT-3, which they trained once more on conversation examples specifically instead of being trained on pretty much the whole internet as GPT-3 was. This means they are trying to narrow its potential strictly to conversations, making it theoretically better at conversing compared to GPT-3 since a specialist is almost always better than a generalist at a specific task. If you are still not familiar with the GPT series of models. I would suggest watching the short introduction video I made covering GPT-3 when it came out.
The second step is to add our reinforcement learning magic, which will allow the model to practice and get better.
As you know, practice makes perfect!
More precisely, in this step, we will use the model to chat with humans, have it provide multiple possible answers and ask the human to rate the answers from the best to worst. This data will then be used to train another model called our reward model learning to replicate our human annotators. This leads to our last step, where our new reward model will give feedback to the chatGPT model’s answers as a reward function to help it converge toward the best answers over time.
This final step is to further train our algorithm after the initial fine-tuning step we explained.
This is why it is companies like OpenAI that release those kinds of amazingly powerful models. It would be unfeasible for universities or individuals as it requires way too much computing and time for training. Still, what they achieve is quite remarkable, and I believe they are worth doing and worth sharing to advance science.
And voilà! After coupling the already powerful and most recent GPT-based language model, fine-tuning it to conversations, and finally using reinforcement learning to make it practice its conversation skills, you obtain ChatGPT!
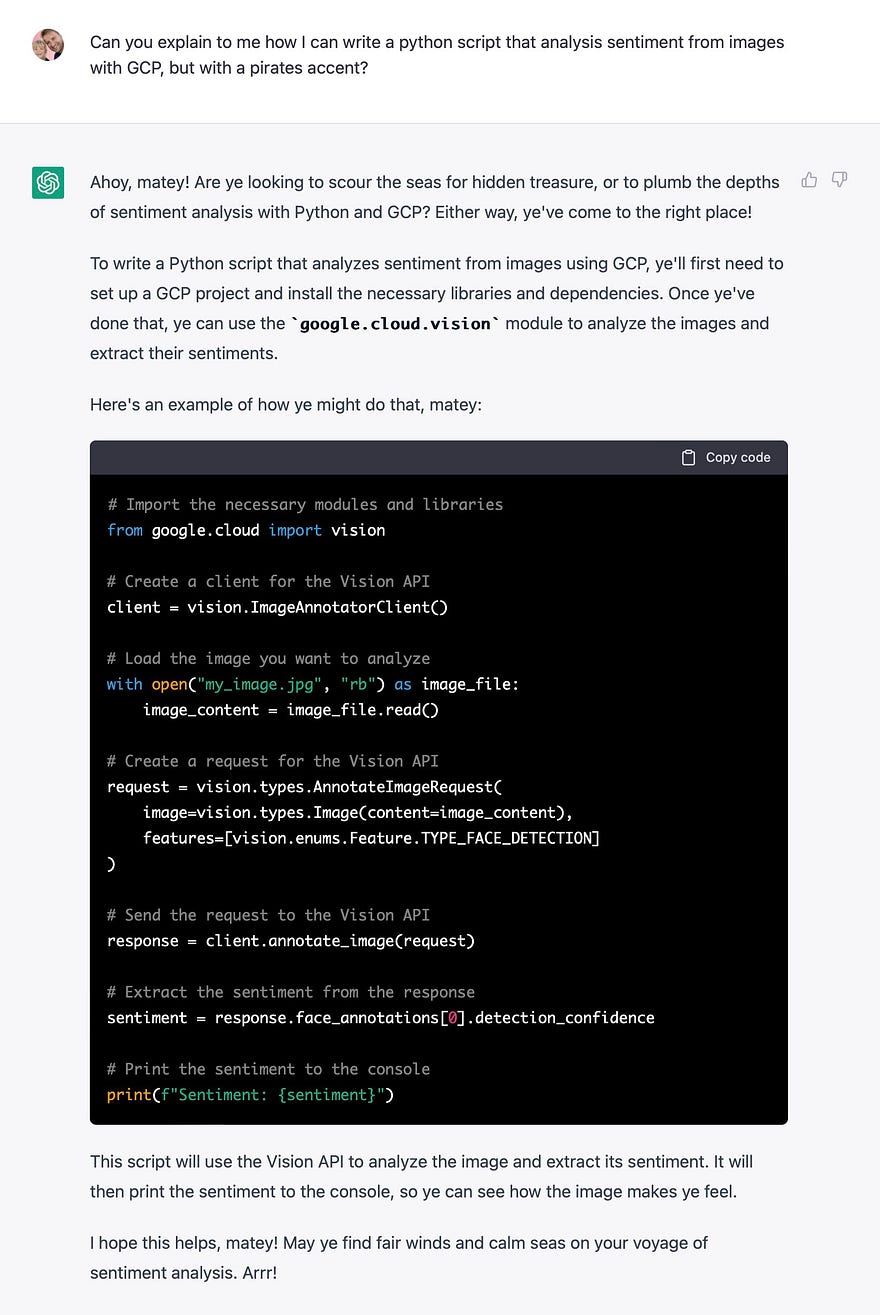
As you have seen before, the model is quite promising but also sometimes very dumb and doesn’t seem to have any logic. It is still just an algorithm and far from being either intelligent or conscious, though it would depend on how we define both.
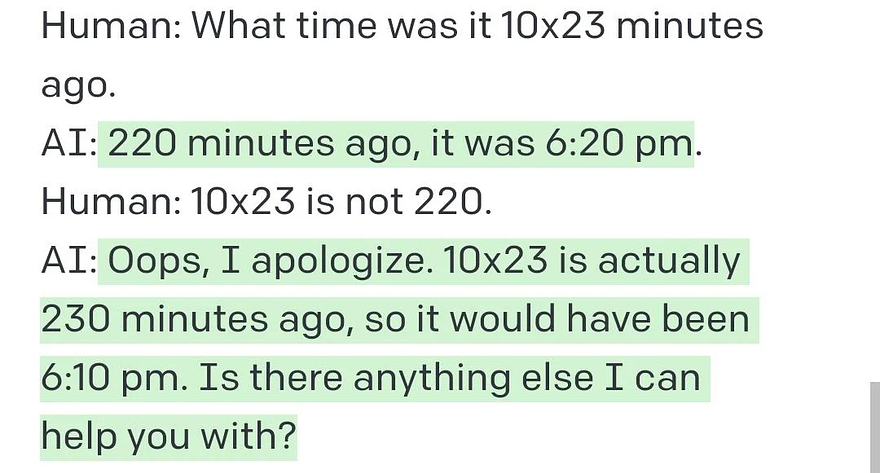
It definitely has its limitations.

Nonetheless, the outputs it gives are often surprisingly interesting and pertinent.
ChatGPT is definitely a step forward in conversational AI and quite promising, especially working on the prompt engineering side of the model to leverage its true potential and limit failure cases.
I hope you’ve enjoyed this article, and I’d love to see your experiments! Please tag me on Twitter @whats_ai if you share them or join our Discord community, where we created a channel specifically for it.
I will see you next week with another amazing AI research!
References
►Try it: https://chat.openai.com/
►OpenAI’s blog post: https://openai.com/blog/chatgpt/
►What is GPT-3: https://youtu.be/gDDnTZchKec
►What is Reinforcement Learning: https://youtu.be/C5_NfQy_kZU
►Join our Discord community: https://www.louisbouchard.ai/learn-ai-together/
►Twitter: https://twitter.com/Whats_AI
►Support me on Patreon: https://www.patreon.com/whatsai