How to Improve Your RAG Pipeline with Fine-Tuned Embedding Models
Is fine-tuning an embedding model worth it?


Watch the video!
Let’s dive into an important part of the Retrieval-Augmented Generation (RAG) pipeline: the embedding model. All the data you have will be entered into embeddings, which we’ll then use to retrieve information. So it’s quite important to understand embedding models. Let’s dive into this crucial part of the pipeline, how to fine-tune them, and why that’s important.
What is an Embedding Model?
So, what exactly is an embedding model? In RAG, our first step is to convert all documents or text into numerical representations. This process is called creating embeddings. An embedding model takes in unstructured data and converts it into these numerical representations.
The cool thing about embeddings is that they give us fixed-length representations or numbers for words our words, no matter how many different words there are in the given text. And here’s the key part: when the model converts the text, it keeps similar meanings close together. Embedding models convert the text or even images or audio as for GPT-4o, which are high-dimensional, into our lower-dimensional representation, which we call embeddings or also latent space, which is where the embeddings lie. This latent space captures the important features and similarities in a simpler form. For example, an embedding model might take a 2000-word document and represent it in 300-dimensional space, meaning simply 300 numbers in a list, which is much smaller than the original space but still retains the meaningful relationships between words.
Embedding models are useful because they can understand the relationships between words rather than just looking at each word on its own. This makes them essential for text and image search engines, recommendation systems, chatbots, fraud detection systems, and many more applications.
Embedding Models vs. Vector Databases
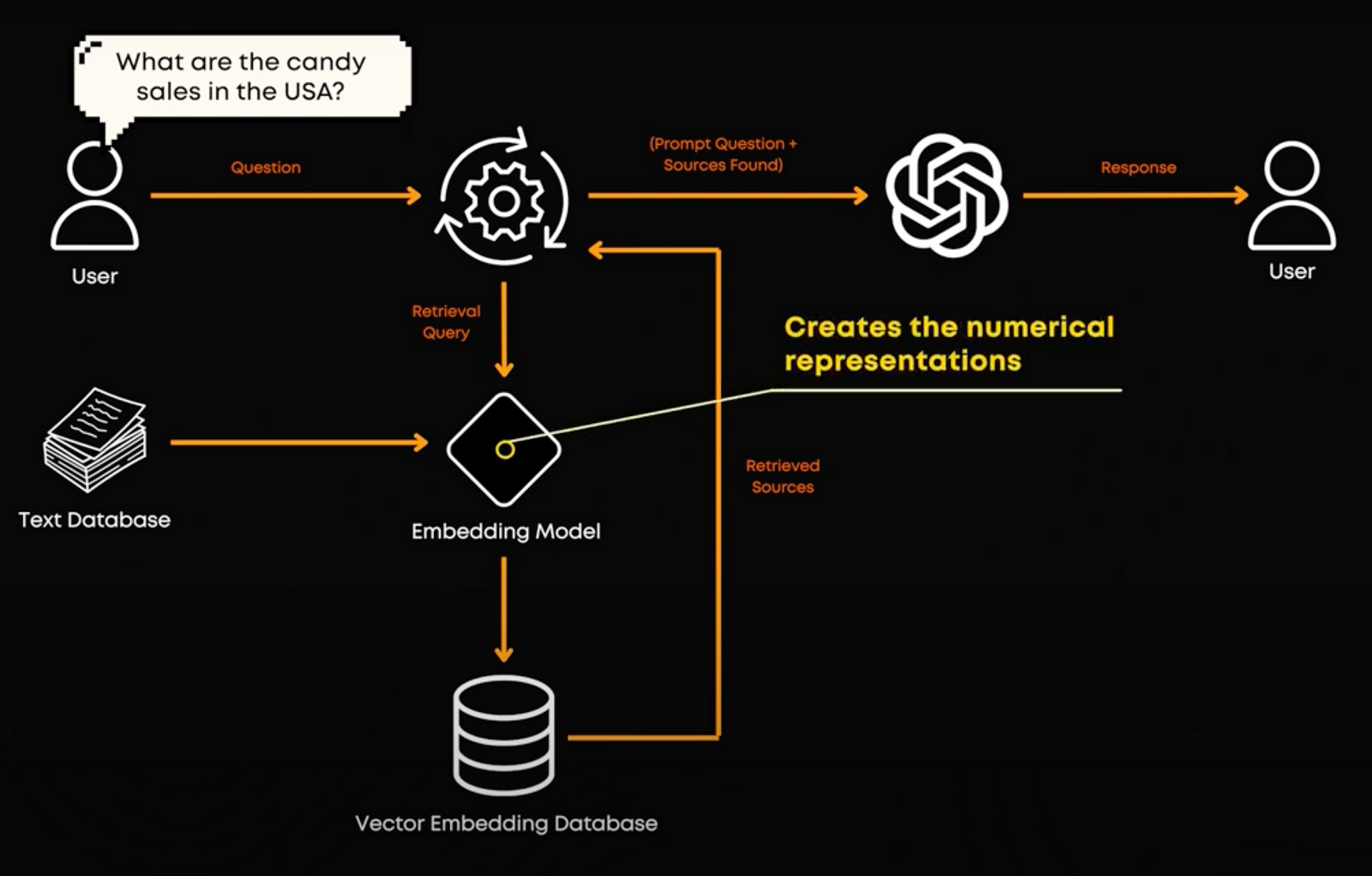
Now, if you’ve followed the course or read the other articles, you might be thinking, “This sounds a bit like what vector databases do.” So, what’s the difference?
A vector database is all about storing and retrieving these embeddings efficiently. So it works with them. Once our embedding model has done its job and converted text into embeddings, the vector database steps in. It organizes and indexes these embeddings so that when we make a new query, we re-use our embedding model to embed the query, and then use our database to quickly find and return the most relevant information. In short, the embedding model creates the numerical representations, and the vector database stores and retrieves them based on their contextual similarities by simply comparing the numbers together.
Matryoshka Embeddings
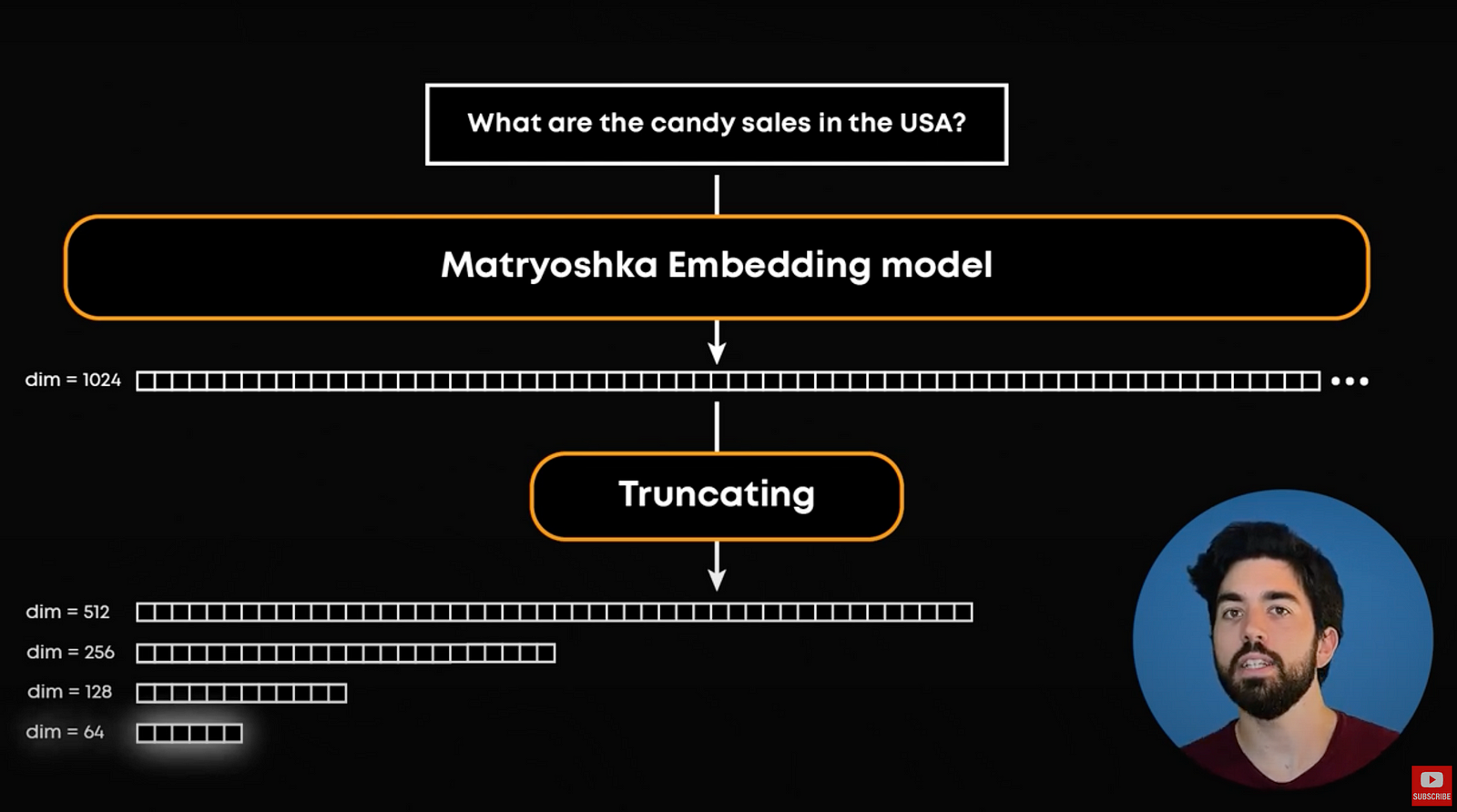
Since we took a small detour to talk about vector databases, let’s talk a bit about storage. High-dimensional embeddings can be expensive to store. They can have thousands of values and we can have millions of them. This is where Matryoshka Embeddings come in handy. Imagine Russian nesting dolls: they start big and get smaller as you open each one. Matryoshka Embeddings work similarly. They start with a large size, say 1024 dimensions, and gradually reduce during training to something smaller, like 64 dimensions. By the end of training, even these smaller embeddings can capture the essential meaning of the text just as well as the larger ones. We can then compare the smaller ones, starting with 64 to find the most similar embeddings, and then re-run a search on a larger representation like 128 to find the most similar ones from the subgroup and repeat this process until we reach the larger dimensions, like our 1024 we started with. This useful approach makes the storage and computation during training and fine-tuning much more efficient without losing quality.
Fine-Tuning an Embedding Model
Let’s get back to our embedding models. We’ve covered what embedding models are, how they work, how they are used and how we store the final embeddings they produce. Now, let’s talk about fine-tuning them. While general embedding models are great, they might not be perfect for specific tasks right out of the box.
Imagine you have an embedding model trained on a wide variety of texts. If you want it to perform well on a specific task, like understanding customer support tickets for your company, you may need to fine-tune it. Fine-tuning adjusts the model to better capture the nuances and specifics of your task. For example, a chatbot fine-tuned on your customer support tickets will understand your customers’ typical issues and be able to respond more effectively.
What Happens During Fine-Tuning?
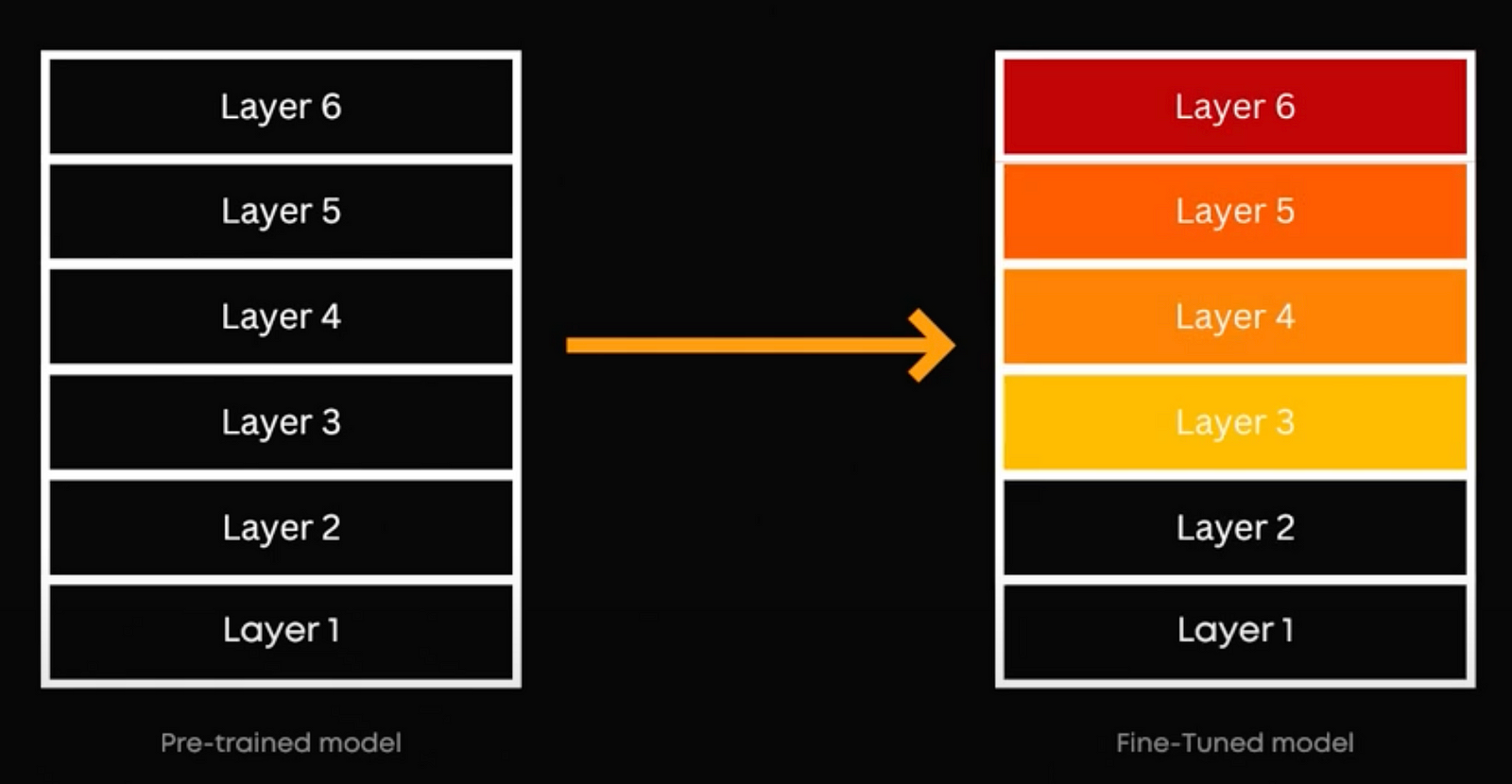
So, what actually happens when you fine-tune your embedding model? Initially, a pre-trained embedding model has a general understanding of language, with data uniformly distributed across its layers. Fine-tuning tweaks this distribution to focus more on your specific task. This means the model’s latent space, which is that simpler numerical representation we talked about, gets adjusted to form more relevant and task-specific clusters. It will learn to better split the data even in a specific field, whereas it would’ve all been very similar using a more general model.
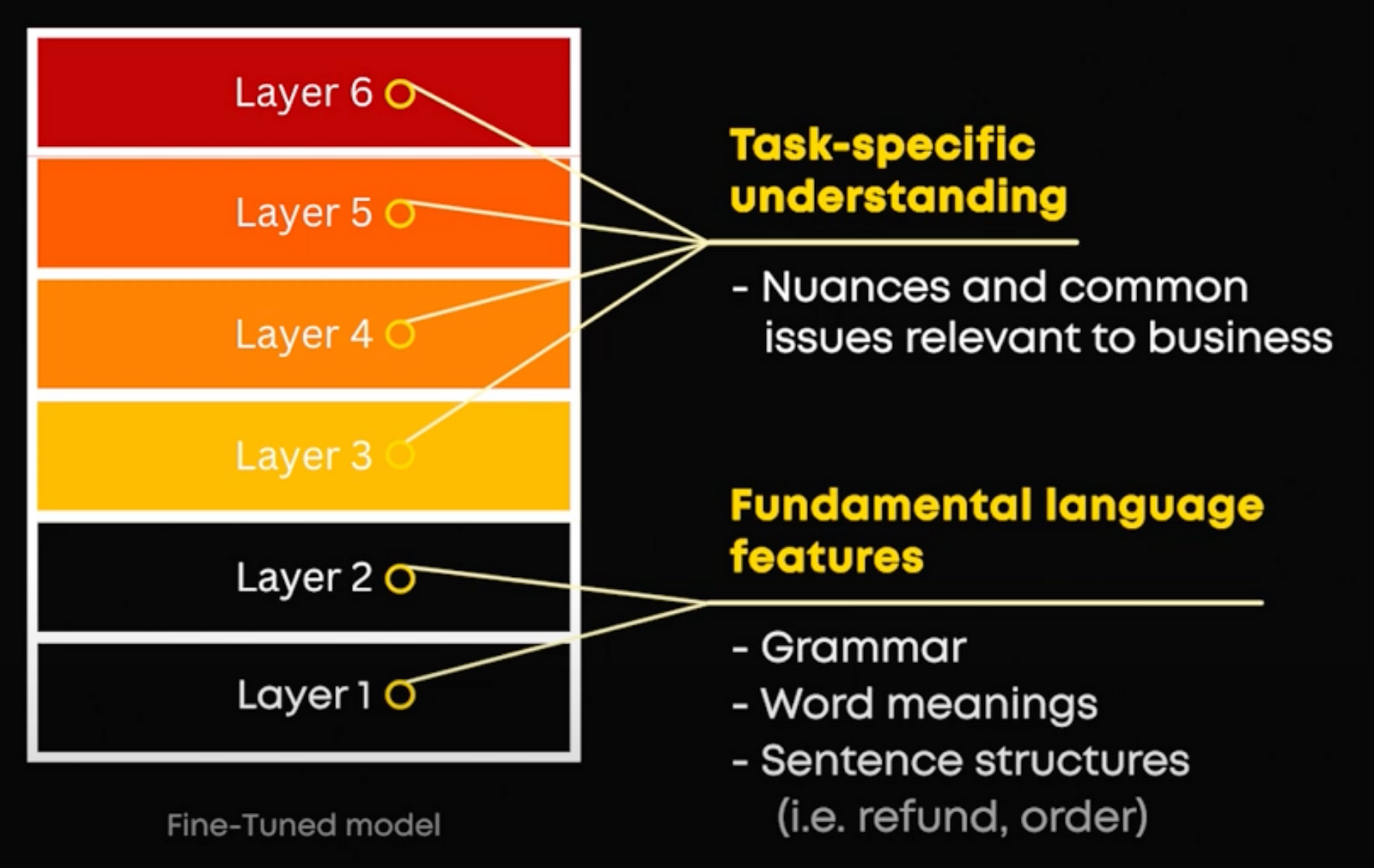
In general, the lower layers of a pre-trained model capture fundamental language features, while the upper layers develop task-specific understanding during fine-tuning. For example, in our customer ticket situation, the lower layers capture fundamental language features like grammar, word meanings, and basic sentence structures. For example, they recognize terms like “refund” and “order.” However, without fine-tuning, the model’s upper layers only have a general understanding of customer service contexts. When fine-tuned on your specific dataset of customer support tickets, the upper layers of the model adjust to understand the particular nuances and common issues relevant to your business. This means the model can recognize specific problems and provide responses based on the given context. It can effectively handle a ticket like “I need help with my recent order; it hasn’t arrived yet” by identifying it as a delivery issue not arriving based on past similar tickets and finding the right information from the database to give the appropriate answer to the customer, instead of taking out all the information related to the word “order” for example. This makes a fine-tuned embedding model better at handling context-specific tasks compared to a generalized model.
How to Fine-Tune an Embedding Model
Fine-tuning an embedding model involves a few steps:
- Select a Pre-trained Model: Start with a model that already performs well on general tasks.
- Prepare Your Data: Gather and preprocess data that’s specific to your task.
- Adjust the Model: Re-train (or fine-tune) the model on your dataset, often using transfer learning techniques.
- Evaluate and Optimize: Test the model’s performance and tweak it to improve accuracy.
- Integrate with RAG System: Once the model is fine-tuned, integrate it into your RAG system. Ensure the embedding model effectively converts incoming queries and documents into embeddings that the vector database can efficiently retrieve and match.
Do You Really Need to Fine-Tune?
But do you always need to fine-tune an embedding model? Not necessarily. If a general pre-trained model meets your needs, you might not need to fine-tune it. This is why evaluating your pipeline properly is essential, even right at the start of the project. But if your task requires a deeper understanding of specific contexts or nuances, fine-tuning is crucial. It helps the model produce more relevant and accurate embeddings that will be tailored to your specific needs and better understand the domain-specific differences to find relevant information.
So, fine-tuning can significantly enhance the model’s performance by making it more aligned with your task, leading to better and more precise results. It’s extremely useful when your task requires extensive expert knowledge not present in the default embedded system or LLM you are using.
Check out our course, which covers advanced RAG techniques and much more for producing an LLM-based system. Use the code “BLACKFRIDAY_2024” for 15% off!
Thank you for reading, and I’ll see you in the next one!
Resources:
- https://cloud.google.com/vertex-ai/generative-ai/docs/models/tune-embeddings#:~:text=Tuning a text embeddings model,suited to your specific needs.
- https://www.datarobot.com/blog/choosing-the-right-vector-embedding-model-for-your-generative-ai-use-case/#:~:text=Vector databases are often not,the system faster and leaner.
- https://ar5iv.labs.arxiv.org/html/2210.12696v1
- https://huggingface.co/blog/matryoshka
- https://www.ibm.com/topics/embedding