How Apple Photos Recognizes People in Private Photos Using Machine Learning
Using multiple machine learning-based algorithms running privately on your device, Apple allows you to accurately curate and organize your images and videos on iOS 15.


Watch the video and support me on YouTube
In a recent publication, Apple explained how they used machine learning to directly recognize people in private photos on your iPhones and iPads without having access to your images to train their algorithms.
For those of you with Apple products, you can actually research by the person in the Photos app.
Indeed, using multiple machine learning-based algorithms that I will cover in this article, running privately on your device, you are able to accurately curate and organize your images and videos on iOS 15. It will recognize the different people and allow you to research in your pictures where the person appears. If you have thousands of photos like I do, you will already have different clusters each representing different people. For example, one such cluster could be all the photos where your friend John is in so that you can name it “John” and then search for images of John in your pictures to have them appear automatically. It can even recognize photos where the same people frequently appear, even if it doesn’t know the persons individually or hasn’t been directly trained with it, and use it to share memories like the “Together” feature shown here. This is a super cool built-in application by Apple, and the best is that it even works when the face is occluded or sideways, as we will see.
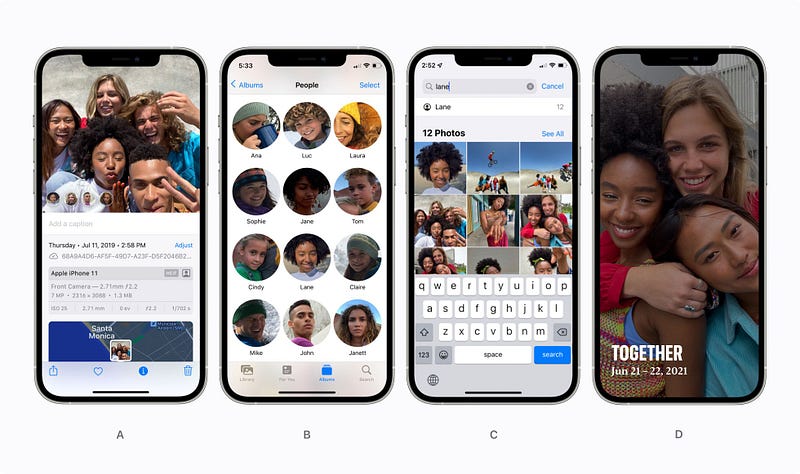
As I said, it seems to work really well. It entirely runs on your device privately, and they are always improving the algorithms, but it’s even cooler to know how it works, so let dive into it! This task of recognizing people in your own picture is extremely challenging because of the variability your photos will have. Different people, different angles, different scales, different lightings, occlusions because your friend was catching a football, or even from other cameras. If we would strictly base ourselves on the person’s face, this would be pretty incomplete as most of our pictures taken on the spot during an event aren’t perfect images with your friends smiling in front of the camera. When you type in John, you’d like to see these events where John won the game by catching this ball.
To attack this, they start by locating the faces and upper bodies of people visible in the image using a first detection algorithm. This algorithm was trained on many labeled human examples annotated with where the bodies and the faces were. Meaning that they trained a deep neural network with images sent as inputs, and the outputs were only the cropped version of the image with either the bodies or faces of the people. This is done by feeding many examples to the network, helping it showing where to focus its attention with the correct identified sections. This way, it can iteratively learn to find this body part by itself afterward if we show it enough examples during training.
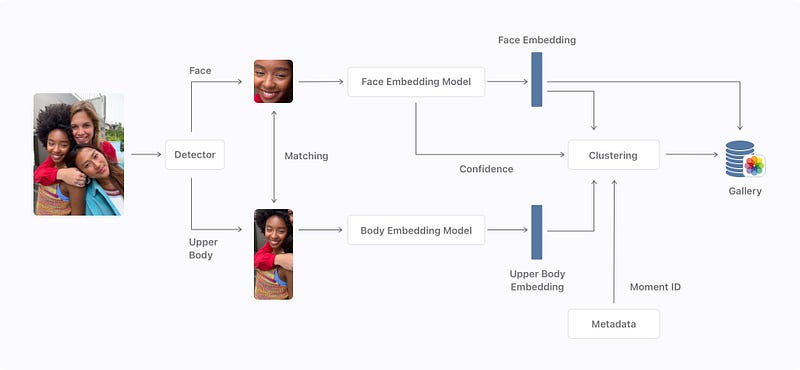
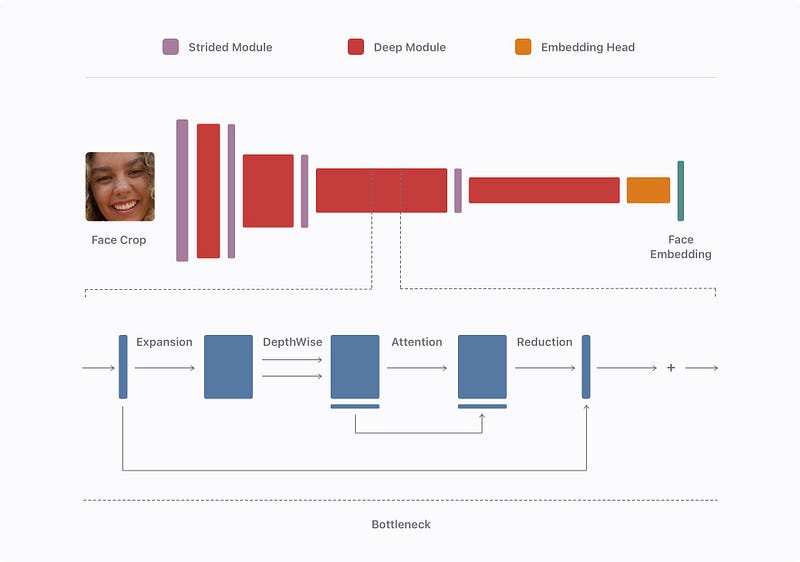
Then, they match the bodies and faces of each individual to have even more data about the person in case only one of the two appears in a future image. You can see here that both the body and face are sent into a separate model that encodes the information, creating embeddings. These embeddings are simply the most valuable information about the face and body of the person. Here, we use another network to encode the information because we want our embeddings to be similar for the same person and different for different individuals. This is again done with another model that will look like this, inspired by mobilenet, which I talked about in my convolutional neural network article. It is a lightweight convolutional neural network that can run extremely efficiently, made for mobile instead of GPUs. If you are not familiar with CNNs, I strongly invite you to read the article I wrote explaining them simply. Basically, it takes the cropped images and compresses the information in a smaller space focusing on the most interesting details about the individual. This is possible because such a model was trained on a lot of images to do exactly that. Then, these embeddings are merged and saved in your phone’s gallery unless they have poor responses. These poor responses may come from unclear faces or upper bodies and would be automatically filtered out.
This is repeated with all your pictures to create clusters out of these embeddings. These clusters will be the different people identified. It will merge all similar embeddings in small groups where each group is a specific individual. So this is the step where all the pictures where John was identified are put into a gallery. And what’s cool is that this automatically runs during nighttime when your phone charges while you sleep and keeps on improving the more pictures you have.
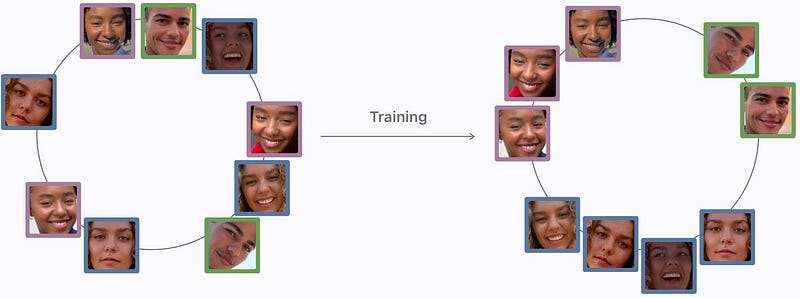
So once these clusters are created, your new photos containing people are sent to the same deep network to create a new embedding per person in the image. This new embedding will either join a cluster if they find a match or create a new one based on the difference between the embeddings you have in your phone and the new picture’s embeddings.

Here, to find whether it is the same person or not, they focus primarily on the face. If it’s occluded or sideways, it uses the upper body coupled with what we have from the face and takes the time of the photo into account to measure if the clothing could be the same or different. As you may suspect, the upper body isn’t always helpful. As they say, “We’ve carefully tuned the set of face and upper body distance thresholds to get the most out of the upper body embedding without negatively impacting overall accuracy.” And this is how Photos regroup your friends within the application without you knowing it!
Another concern was that they want to offer the same experience for all Apple users no matter the photographic subject’s skin color, age, or gender. It is great that they keep on improving the generalization and working to remove these biases from their algorithm the best they can using the broadest datasets possible and data augmentation to add variations to the training images. If you have an iPhone or iPad, please let me know what you think of this feature in the Photos app and how well it works!
Thank you for reading!
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
References:
- Apple, “Recognizing People in Photos Through Private On-Device Machine Learning”, (2021), https://machinelearning.apple.com/research/recognizing-people-photos