Lessons from Minitron
Pruning and Distillation Best Practices


Watch the video!
We’d all love to build a model from scratch like Llama, but how realistic is that? The computing, architecture, and training data they have access to are so vast that it’s fair to say most of us wouldn’t be able to replicate it. But is it really necessary to train such large models from scratch anyway? What if the big companies just created one big model, and then we, the normal people, could use it to train smaller models that each of us would use for our specific tasks or data? Well, that’s exactly Llama’s goal with the release of the 405B model and leveraging distillation to train the smaller ones. Likewise, Nvidia recently released two papers that explore this exact amazing idea with their Minitron approach.
Good morning, everyone! I’m Louis-Francois, the CTO and Co-Founder of Towards AI, and in this article, we’ll discuss the basics of knowledge distillation and the other techniques like pruning and quantization that can help you build models with limited resources.
I know I just mentioned a lot of terms, so let’s break them down step by step. Large language models often have sparse parameters, meaning many of them might not hold much value — some are even zeros, with little to no impact on the model’s performance. The process of identifying and removing these unnecessary weights is called pruning. By reducing the number of parameters, we also shrink the activation size, which refers to the number of components that determine importance. Additionally, we can speed up the model by reducing the bit size, a process known as quantization. As seen in other videos and in the course, these two steps are necessary to optimize models. But more importantly, knowledge distillation allows you to teach smaller models (student models) based on the knowledge of larger ones (teacher models).
Let’s break down each step and how it’s applied.
For pruning, three key metrics help identify which parts of the model can be removed:
- The Taylor gradient approach assesses the importance of model weights by analyzing their contribution to the loss function. Using Taylor expansion, we can estimate weight sensitivity and remove those that have a minimal impact on performance.
- Then we have Cosine similarity. This metric measures how similar neurons or layers are within the model. If two components are highly similar, one can be removed without affecting performance.
- Finally, we have Perplexity. This evaluates how well the model predicts samples. Lower perplexity means better predictions, so when pruning, researchers check how removing parts affects the model’s perplexity on a calibration dataset.
These metrics help identify which parts of an LLM can be removed to reduce size and computational requirements while keeping performance as high as possible.
A great way to analyze this is by evaluating attention, focusing on three key methods: width, depth, and iterative importance.
But first, let’s quickly revisit how a transformer model works. It starts with the input being processed by an embedding layer, which transforms the text input into tokens. These tokens are then passed into the multi-head attention layer, where multiple heads focus on different relationships within the input — like determining which words are related or need attention.
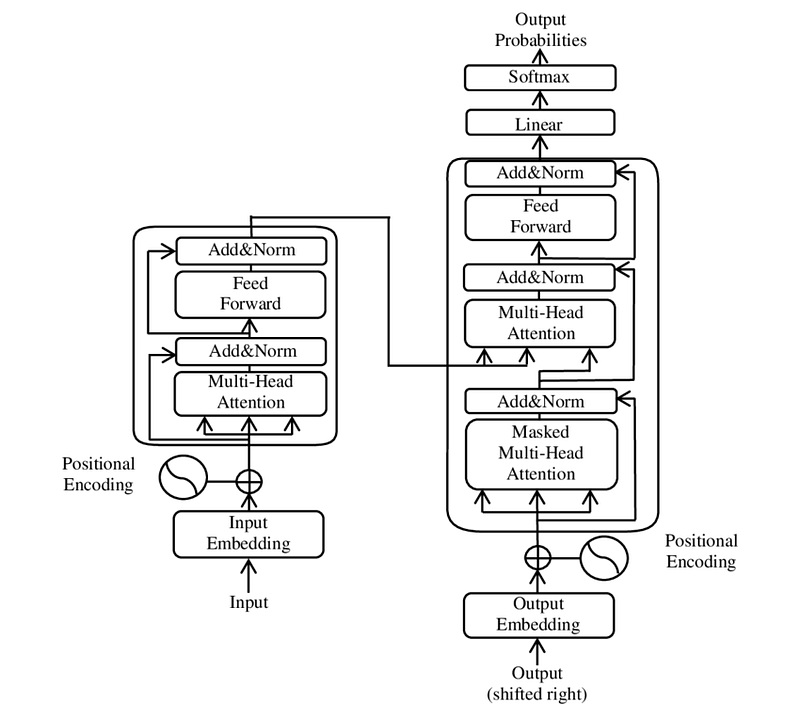
Next, a normalization layer ensures balance before the tokens move to the multi-layer perceptron, which converts linear input into non-linear insights, helping the model gain a deeper understanding. After another normalization step, this process repeats through several layers, and the final output goes through a softmax layer, producing probabilities for the given task.
Now, back to pruning and the three key methods:
- Here, width pruning focuses on evaluating multi-head attention, multi-layer perceptron, and LayerNorm layers. A small dataset helps assess the importance of each head, neuron, and layer, with mean, variance, and L2 norms being calculated to guide pruning.
- We then have depth pruning. This method measures the importance of entire layers using metrics like perplexity and block importance. Perplexity helps gauge the sensitivity of each layer by testing how its removal affects output. Block importance uses cosine similarity to measure the layer’s role from input to output.
- Lastly, we have iterative Importance. Here, pruning and recalculating importance are done step by step. At each iteration, the size is gradually reduced while recalculating importance to ensure consistent pruning over multiple steps.
Once the important parts are identified, pruning begins. For neuron and head pruning, we focus on multi-head attention and multi-layer perceptron layers, while embedding channel pruning involves all three components. When an attention head is removed, the residual information from that head is added back to the remaining heads, ensuring that important information isn’t lost, and performance remains unaffected.

Now that the pruning is complete, how do we find the best design for the smaller model? They start by narrowing down possible model designs (which is the search space) with a parameter budget to keep the model size manageable. By focusing on common settings for neurons, attention heads, and embeddings, they come up with fewer than 20 possible designs. Quick training on a smaller dataset (around 1.8 billion tokens) helps identify the best-performing candidates. This retraining step ranks the models more accurately, allowing for the best one to be trained further.
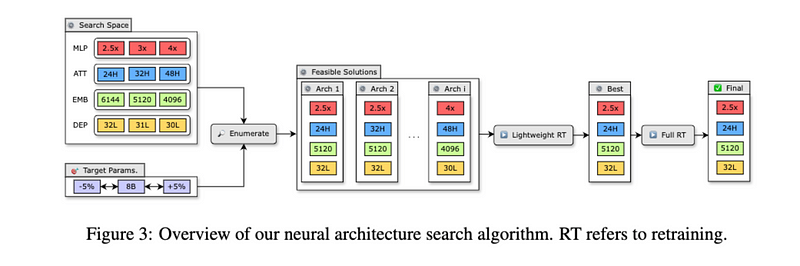
But how does retraining work? When a model is pruned, some information is inevitably lost, leading to decreased accuracy. Retraining helps regain that accuracy. Two strategies are explored in Nvidia’s recent research: (1) conventional training using ground truth labels, and (2) knowledge distillation, where the pruned model (student) learns from the unpruned model (teacher).
Knowledge Distillation is when a smaller model (student) learns from a larger model (teacher) by mimicking its outputs and internal behaviors. The student compares its probability distribution with the teacher’s using a logit-based knowledge distillation loss. It also matches the intermediate hidden states of the teacher model at different layers. Since student and teacher models differ in size, the student’s hidden states are transformed to match the teacher’s using a linear transformation. An adjustable parameter, alpha, controls how much weight is given to this loss. The total loss includes three components: the student’s prediction, the logit-based loss, and the intermediate state-based loss. This approach helps the smaller model retain much of the knowledge from the larger one, making it more efficient without sacrificing accuracy.
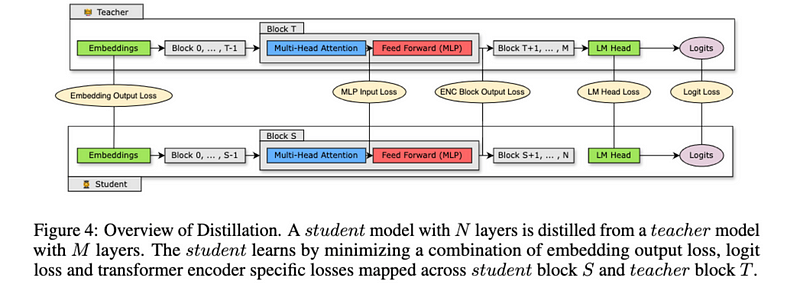
In the paper, they also distilled a few important points to remember while doing this process on your own.

- Train the largest model first, then shrink it through pruning and use knowledge distillation to keep performance intact.
- Use specific formulas (L2 and mean) to determine which parts of the model to prune in width, and use perplexity or block importance for depth pruning.
- Calculate importance just once instead of multiple times to save time without sacrificing accuracy.
- Favor width pruning over depth pruning for models smaller than 15B parameters.
- After pruning, retrain using knowledge distillation with KLD to retain performance.
- Use logit, state, and embedding distillation when reducing layers significantly.
- For smaller depth reductions, use logit-only distillation.
- Prune the model as close as possible to your target size for easier retraining.
- Do a small amount of retraining to stabilize the pruned model’s performance.
- If the model was trained in multiple phases, prune after the last phase for the best results.
Let me walk you through how they managed to apply the above Minitron compression strategy to two big models: Llama 3.1 (8B parameters) and Mistral NeMo (12B parameters), and successfully shrink them down to more efficient versions — 4B and 8B parameters, respectively. The whole process is fascinating because not only did they make these models smaller and faster, but in some cases, they even made them more accurate! So, let’s break it down step by step.
First Up: Teacher Correction
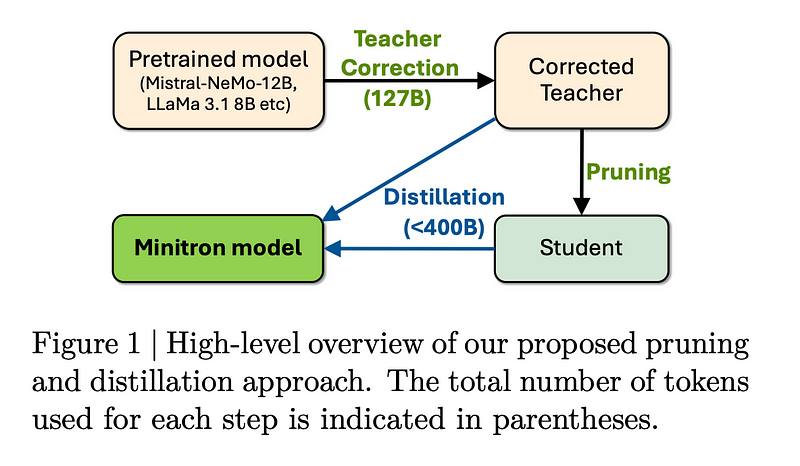
One of the challenges they had in these experiments was that they didn’t have access to the original training data for these models. So, they had to do something called teacher correction. This means they took the large, uncompressed model (the teacher) and fine-tuned it on their own dataset. This step is crucial because it ensures that when they later try to distill the model, the teacher is up-to-date with the data it’s working with. By doing this, they managed to reduce the validation loss by over 6%! That’s a big improvement, and the cool part is that they could do this teacher correction while also distilling the model without messing with the pruning process.
Next: Pruning and Distillation
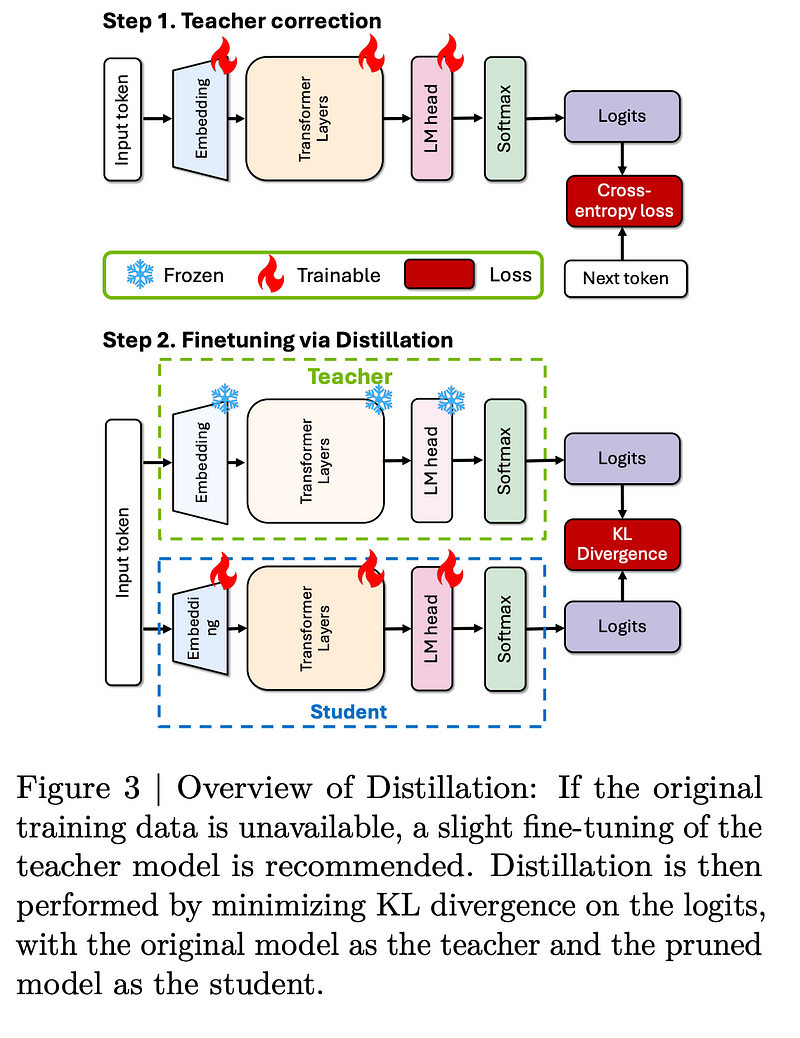
After fine-tuning the teacher model, they moved on to the pruning step, where they started chopping down unnecessary parts of the model to compress it as we discussed earlier. Once that was done, they used distillation to make sure the smaller model recovered any accuracy that might have been lost during pruning. For this, they used the Nemotron-4 CT dataset and found that they only needed 380 billion tokens to achieve state-of-the-art accuracy — which is pretty impressive compared to the trillions of tokens usually needed for large models!
When it came to width pruning (which is focusing on attention heads and pruning other parts like MLP dimensions and embedding channels), they found this method gave them stronger accuracy results.
Mistral NeMo 12B to MN-Minitron-8B: A Win for Compression
Now for the specific examples, when they compressed Mistral NeMo 12B down to an 8B parameter model, they saw some really exciting results. The smaller, compressed model actually outperformed the original teacher model on two benchmarks:
- GSM8k, where the score jumped from 55.7% to 58.5%.
- and HumanEval that went up from 23.8% to 36.2%.
And they achieved this by only using distillation loss during retraining. So, even though they were pruning and cutting down the model, the distillation process helped it regain, and in some cases, exceed its original performance.
Llama 3.1 8B to Llama-3.1-Minitron 4B: Balancing Accuracy and Speed
For Llama 3.1 (8B), they compressed it down to 4B parameters, so half the size, and here’s where it gets interesting. They tried both width pruning and depth pruning to see which worked better. Width pruning came out on top when it came to accuracy, with a score of 60.5% on the MMLU benchmark, compared to 58.7% for depth pruning and 65% for the base model.
But, when they tested reasoning ability, there was a huge difference:
- GSM8K accuracy was 41.24% for width pruning, but it dropped to 16.8% for depth pruning, and 50% for the base model.
However, depth pruning wasn’t all bad — it actually sped things up. Depth pruning gave a 2.7× speedup over the original model, while width pruning gave a 1.7× speedup, which is an amazing speed-up to lose a bit of accuracy. One interesting thing they found was that when they did depth pruning, removing contiguous layers (layers next to each other) was way more effective than removing random layers based on importance.
What Does All This Mean?
So, to wrap it up, they proved that you can take these massive models, shrink them down, and still get state-of-the-art performance — sometimes even better than the original — using smart strategies like pruning and knowledge distillation carefully. It’s a great example of how you can push the limits of what’s possible with AI, especially when you have limited resources. And really good news for all of us!
We discuss these approaches and more about training, fine-tuning and building RAG systems with LLMs in much more depth with applied examples in our RAG course.
Thank you for reading the article throughout the end, and I hope you found it useful!
Resources
LLM Pruning and Distillation in Practice: The Minitron Approach, https://arxiv.org/pdf/2408.11796
Compact Language Models via Pruning and Knowledge Distillation, https://arxiv.org/pdf/2407.14679v1