LLM Developers vs Software Developers vs ML Engineers: Key Differences
The Need for New Skills and Roles


Watch the video!
The Need for New Skills and Roles
The rise of LLMs isn’t just about technology; it’s also about people. To unlock their full potential, we need a workforce with new skills and roles. This includes LLM Developers, who bridge the gap between software development, machine learning engineering, and prompt engineering.
Let’s compare these roles briefly. Software Developers focus on building traditional applications using explicit code. Machine Learning Engineers specialize in training models from scratch and deploying them at scale. LLM Developers, however, operate in a middle ground. They customize existing foundation models, use prompt engineering to guide outputs, and build pipelines that integrate techniques like RAG, fine-tuning, and agent-based systems.
Becoming a great LLM Developer requires more than just technical knowledge. It involves cultivating entrepreneurial and communication skills, understanding economic trade-offs, and learning to integrate industry expertise into tools and workflows. These developers must also excel at iterating on solutions, predicting failure modes, and balancing performance with cost and latency.
The demand for LLM Developers is growing rapidly, and because this field is so new, there are very few experts out there. This makes it a prime time to learn these skills and position yourself at the forefront of this shift.
How Do LLM Developers Differ From Software Developers and ML Engineers?
Building on top of an existing foundation model with innate capabilities saves huge amounts of development time and lines of code relative to developing traditional software apps. It also saves huge amounts of data engineering expertise, machine learning, infrastructure experience, and model training costs relative to training your own machine learning models from scratch. We believe that to maximize the reliability and productivity gains of your final product, LLM developers are essential and need to build customized and reliable apps on top of foundation LLMs. However, all of this requires the creation and teaching of new skills and new roles, such as LLM developers and prompt engineers. And great LLM developers are in very short supply, especially compared to self-proclaimed prompt engineers!
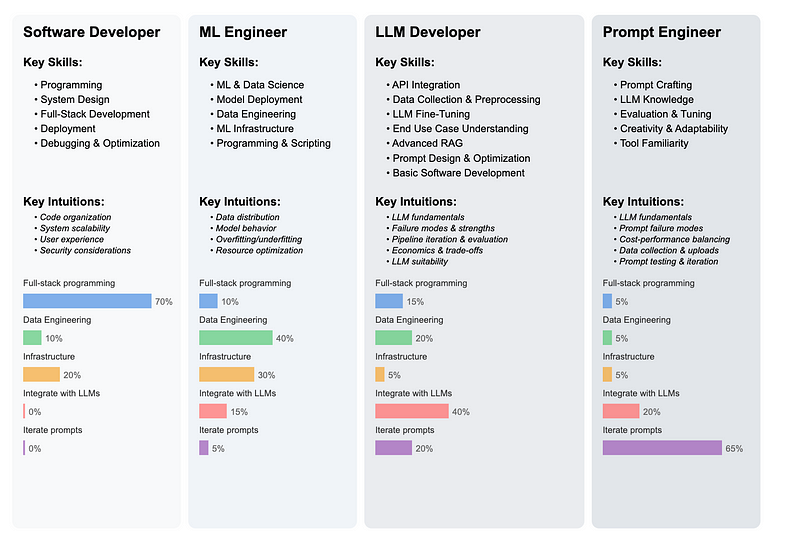
So how do LLM developers differ from software developers and ML engineers?
Software Developers primarily operate within “Software 1.0”, focusing on coding for explicit, rule-based instructions that drive applications. These roles are generally specialized by software language and skills. Many developers have years of experience in their field and have developed strong general problem-solving abilities and an intuition for how to organize and scale code and use the most appropriate tools and libraries.
Machine Learning Engineers are focused on training and deploying machine learning models (or “Software 2.0”). Software 2.0 “code” is abstract and stored in the weights of a neural network where the models essentially program themselves by training on data. The engineer’s job is to supply the training data, often collaborating with data experts, setting the training objective and the neural network architecture to use. In practice, this role still requires many Software 1.0 and data engineering skills to develop the full system. Roles can be specialized, but expertise lies in training models, processing data, or deploying models in scalable production settings. They prepare training data, manage model infrastructure, and optimize resources to train performant models while addressing issues such as overfitting and underfitting.
Prompt Engineers focus on interacting with LLMs using natural language (or “Software 3.0”). The role involves refining language models’ output through strategic prompting, requiring a high-level intuition for LLMs’ strengths and failure modes. They provide data to the models and optimize prompting techniques and performance without requiring code knowledge. Prompt Engineering is most often a new skill rather than a full role — and people will need to develop this skill alongside their existing roles across much of the economy to remain competitive with their colleagues. The precise prompting techniques will change, but at the core, this skill is simply developing an intuition for how to use, instruct, and interact with LLMs with natural language to get the most productive outputs and benefit from the technology.
LLM Developers bridge Software 1.0, 2.0, and 3.0 and are uniquely positioned to customize large language models with domain-specific data and instructions. They select the best LLMs for a specific task, create and curate custom data sets, engineer prompts, integrate advanced RAG techniques, and fine-tune LLMs to maximize reliability and capability. They make the most of all the best technologies out there rather than starting from scratch, which most companies except Google and Meta can’t afford anyway. This role requires understanding LLM fundamentals and techniques and staying aware of the new models and approaches, evaluation methods, and economic trade-offs to assess an LLM’s suitability to target workflows. It also requires understanding the end user and end-use case since they will interact with the LLM in some ways. You are bringing in more human industry expertise into the software with LLM pipelines — and to really get the benefits of customization, you need to better understand the nuances of the problem you are solving. While the role uses Software 1.0 and 2.0, it generally requires less foundational machine learning and computer science theory and expertise.
We think both Software Developers and Machine Learning Engineers can quickly learn the core principles of LLM Development and begin the transition into this new role. This is particularly easy if you are already familiar with Python or similar programming languages. However, becoming a truly great LLM developer requires cultivating a surprisingly broad range of unfamiliar new skills, including some entrepreneurial skills. It benefits from developing an intuition for LLM strengths and weaknesses, learning how to improve and evaluate an LLM pipeline iteratively, predicting likely data or LLM failure modes, and balancing performance, cost, and latency trade-offs. LLM pipelines can also be developed more easily in a “full stack” process, including Python, even for the front end, which may require new skills for developers who were previously specialized. The rapid pace of LLM progress also requires more agility in keeping up to date with new models and techniques.
The LLM Developer role also brings in many more non-technical skills, such as considering the business strategy and economics of your solution, which can be heavily entwined with your technical and product choices. Understanding your end user, nuances in the industry data, and problems you are solving, as well as integrating human expertise from this industry niche into your model, are also key new skills. Finally — LLM tools themselves can at times be thought of as “unreliable interns” or junior colleagues — and using these effectively benefits from “people” management skills. This can include breaking problems down into more easily explainable and solvable components and then providing clear and foolproof instructions to achieve them. This, too, may be a new skill to learn if you haven’t previously managed a team. Many of these new skills and intuitions must be learned from experience. We aim to teach some of these skills, thought processes, and tips in this course — while your practical project allows you to develop and demonstrate your own experience.
If you found this article helpful and see it from outside the course, don’t forget to check out our full course, where we teach you how to build production-ready LLM pipelines and prepare for the future of AI-driven work. Thank you for watching, and we’ll see you in the next one!
