Produce Amazing Artworks with Text and Sketches!
"Make-A-Scene": a fantastic blend between text and sketch-conditioned image generation.


Watch the video and see more results!
This is Make-A-Scene. It’s not “just another Dalle”. The goal of this new model isn’t to allow users to generate random images following text prompt as dalle does — which is really cool — but restricts the user control on the generations.

Instead, Meta wanted to push creative expression forward, merging this text-to-image trend with previous sketch-to-image models, leading to “Make-A-Scene”: a fantastic blend between text and sketch-conditioned image generation. This simply means that using this new approach, you can quickly sketch out a cat and write what kind of image you’d like, and the image generation process will follow both the sketch and the guidance of your text. It gets us even closer to being able to generate the perfect illustration we want in a few seconds.

You can see this multimodal generative AI method as a Dalle model with a bit more control over the generations since it can also take a quick sketch as input. This is why we call it multimodal: since it can take multiple modalities as inputs, like text and an image, a sketch in this case, compared to Dalle, which only takes text to generate an image. Multimodal models are something super promising — especially if we match the quality of the results we see online — since we have more control over the results, getting closer to a very interesting end goal of generating the perfect image we have in mind without any design skills.
Of course, this is still in the research state and is an exploratory AI research concept. It doesn’t mean what we see is unachievable. It just means it will take a bit more time to get to the public.
The progress is extremely fast in the field, and I wouldn’t be surprised to see it live very shortly or a similar model from other people to play with. I believe such sketch and text-based models are even more interesting, especially for the industry, which is why I wanted to cover it on my channel even though the results are a bit behind those of Dalle 2 we see online. And not only for the industry but for artists too. Some used the sketch feature to generate even more unexpected results than what Dalle could do.
We can ask it to generate something and draw a form that doesn’t represent this specific thing, like drawing a jellyfish in a flower shape, which may not be impossible to have with dalle, but much more complicated without sketch guidance as the model will only reproduce what it learns from, which comes from real-world images and illustrations.

So the main question is, how can they guide the generations with both a text input, like Dalle, and a Sketch simultaneously and have the model follow both guidelines? Well, it is very, very similar to how Dalle works, so I won’t enter too much into the details of generative models as I’ve covered at least five different approaches in the past two months, which you should definitely watch if you haven’t yet as these models like Dalle 2 or Imagen are quite fantastic.
Typically, these models will take millions of training examples to learn how to generate images from text with data in the form of images and their captions scrapped from the internet.
Here, during training, instead of only relying on the caption, generating the first version of our image and comparing it to the actual image, and repeating this process numerous times with all our images, we will also feed it a sketch. What’s cool is that the sketches are quite easy to produce for training: simply take a pre-trained network you can download online and perform instance segmentation.
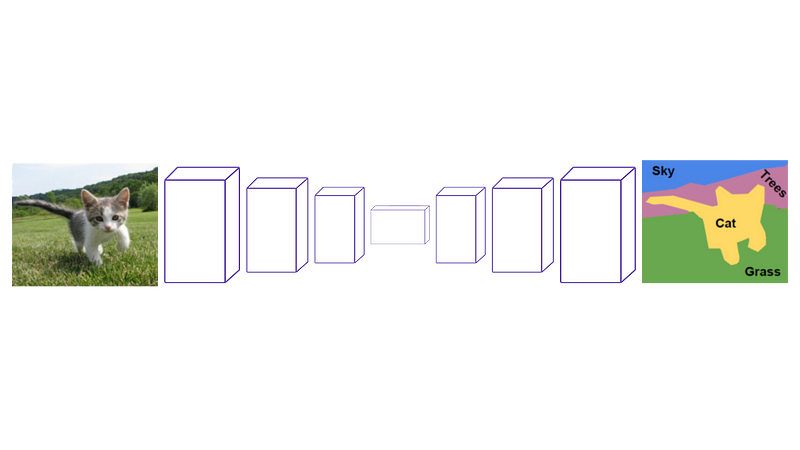
For those who want the details, they use a free pre-trained VGG model on Imagenet, so a quite small network compared to those today, super accurate and fast, producing results like this (see image above)…
Called a segmentation map. They simply process all their images once and get these maps for training the model.
Then, use this map as well as the caption to orient the model to generate the initial image. At inference time, or when one of us will use it, our sketch will replace those maps.
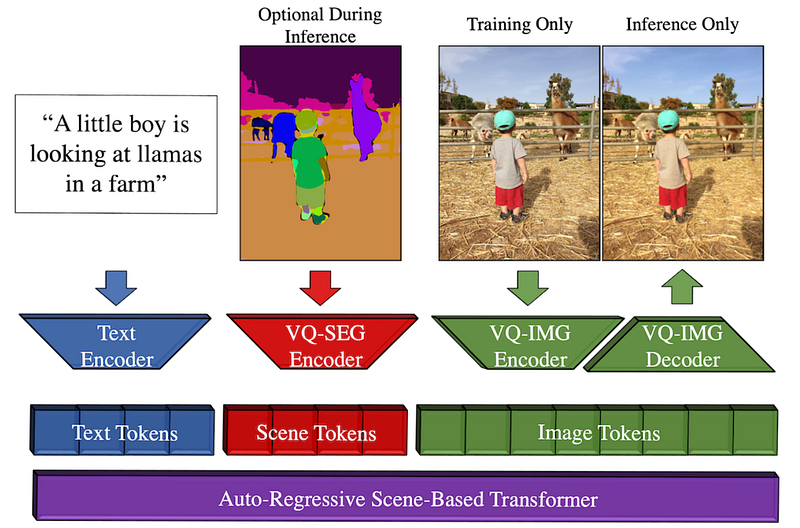
As I said, they used a model called VGG to create fake sketches for training. They use a Transformer architecture for the image generation process, which is different from Dalle-2, and I invite you to watch the video I made introducing transformers for vision applications if you’d like more details on how it can process and generate images.
This sketch-guided Transformer is the main difference with Make-A-Scene, along with not using an image-text ranker like CLIP to measure text and image pairs, which you can also learn about in my Dalle video. Instead, all the encoded text and segmentation maps are sent to the Transformer model. The model generates the relevant image tokens, encoded and decoded by the corresponding networks, mainly to produce the image. The encoder is used during training to calculate the difference between the produced and initial image, but only the decoder is needed to take this Transformer output and transform it into an image.
And voilà!
This is how Meta’s new model is able to take a sketch and text inputs and generate a high-definition image out of it, allowing more control over the results with great quality. And as they say, it’s just the beginning of this new kind of AI model. The approaches will just keep improving both in terms of quality and availability for the public, which is super exciting.
Many artists are already using the model for their own work, as described in Meta’s blog post, and I am excited about when we will be able to use it too.
Their approach doesn’t require any coding knowledge, only a good sketching hand, and some prompt engineering, which means trial and error with the text inputs tweaking the formulations and words used to produce different and better results.
Of course, this was just an overview of the new make-a-scene approach, and I invite you to read the full paper linked below for a complete overview of how it works.
I hope you’ve enjoyed this article, and I will see you next week with another amazing paper!
Louis
References
►Meta’s blog post: https://ai.facebook.com/blog/greater-creative-control-for-ai-image-generation
►Paper: Gafni, O., Polyak, A., Ashual, O., Sheynin, S., Parikh, D. and Taigman, Y., 2022. Make-a-scene: Scene-based text-to-image generation with human priors. https://arxiv.org/pdf/2203.13131.pdf
►My Newsletter (A new AI application explained weekly to your emails!): https://www.louisbouchard.ai/newsletter/