How Nvidia trained Nemotron
Training LLMs with Synthetic Data

Watch the video
Have you ever wondered why training large language models is such a massive challenge? The secret is the enormous amount of high-quality data these models need. But getting that data is incredibly tough. While many people have tried to solve this problem in various ways, one of the most promising approaches is using synthetic data. It’s less expensive than other methods, but it does have a major drawback: the lack of diversity. Recently, Nvidia’s new LLMs from their Nemotron family of models have addressed this issue. They’ve shared a pipeline for generating synthetic data that’s used for training and refining large language models (LLMs).
This is Louis-François, co-founder of Towards AI, where we build and share educational content like our recent book or free videos like this one. In today’s video, we dive into Nvidia’s key learnings and insights for training an LLM using synthetic data.
The first step in creating a synthetic dataset is to generate synthetic prompts, and for that, they built a model generator. One of the big challenges with synthetic data is its lack of diversity from these prompts generating new content. To tackle this, Nvidia controlled the prompts distribution to cover a wide range of scenarios thanks to a few tricks.
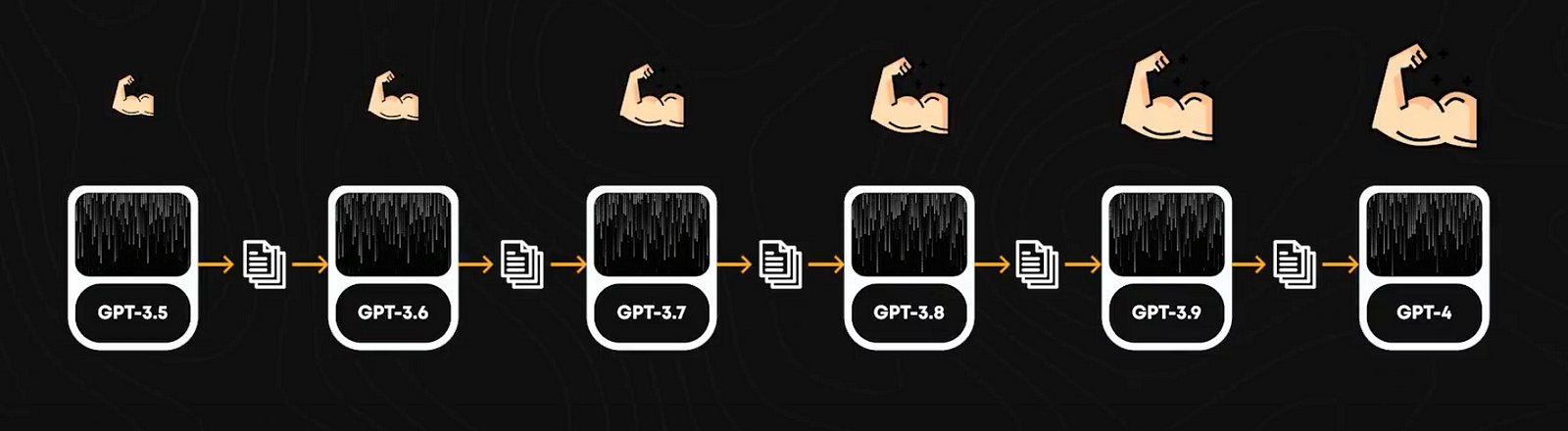
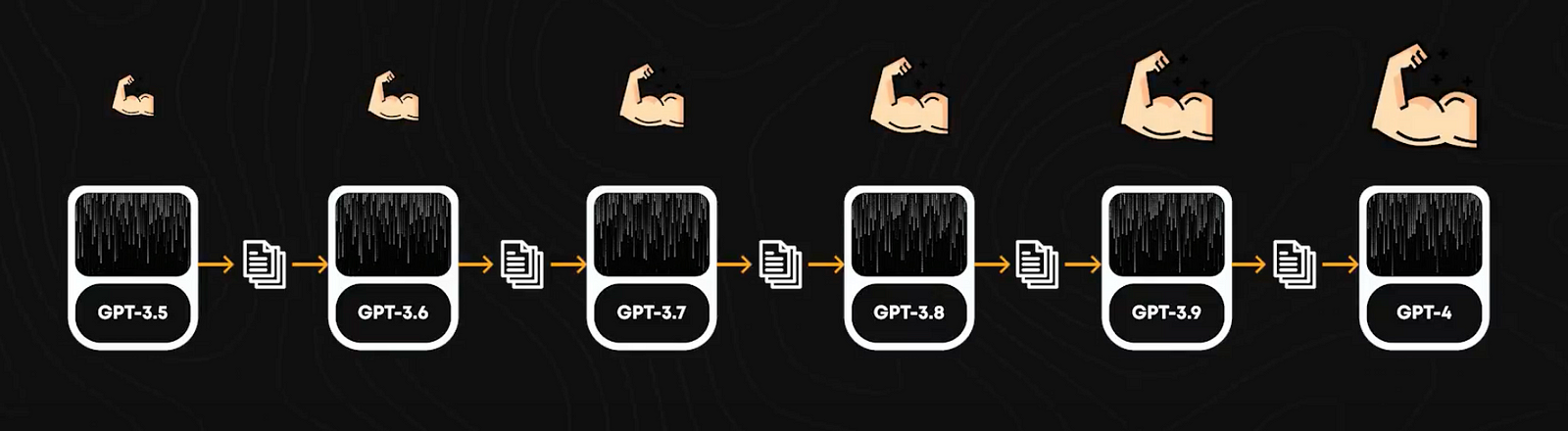
The first thing they used was a method called iterative weak-to-strong alignment. It starts with a strong initial model to produce synthetic data, which is then used to train a new, better model. It would be like using GPT-3.5 to train GPT-4. This process repeats in cycles: each improved model generates higher-quality data, which in turn trains an even better model. We would basically go from GPT 3.5 to 3.6 to 3.7, etc. This continuous loop of data generation and model training results in progressively stronger models. Every improved model is then used to create prompts for data creation for training the next one.
Okay, so that’s cool and all; we’ve got a way to create better models with little manual data improvement work. But how did they fix our prompt distribution issue?
Well, they’ve used several prompt engineering techniques, which we also cover in our book Building LLMs for Production with more essential insights for training and working with LLMs.
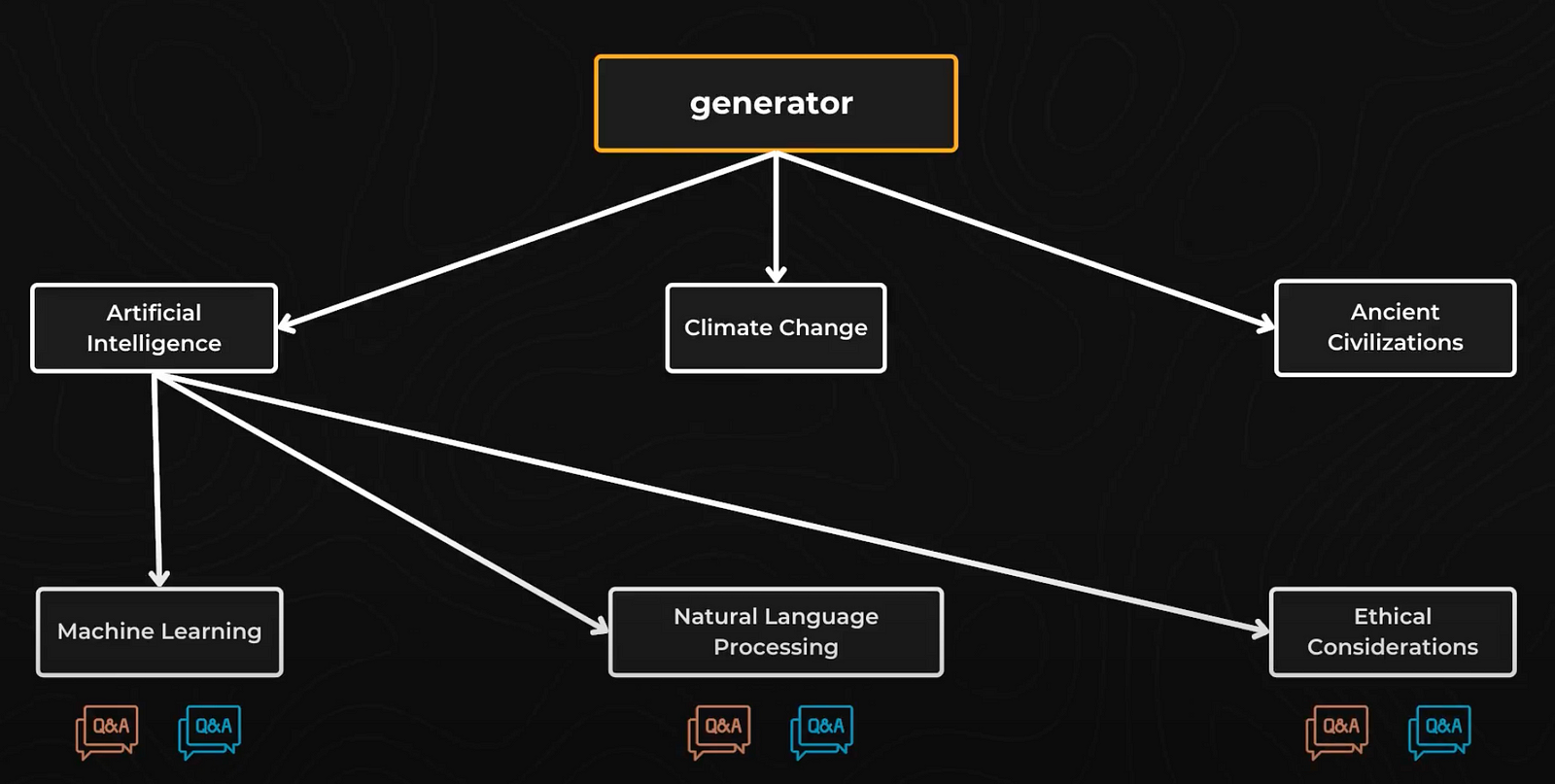
The first technique used is single-turn prompts. Here, a generator creates various macro topics such as “Artificial Intelligence,” “Climate Change,” and “Ancient Civilizations.” Each macro topic is divided into subtopics. For instance, under “Artificial Intelligence,” subtopics might include “Machine Learning,” “Natural Language Processing,” and “Ethical Considerations.” Questions are then created for each subtopic.
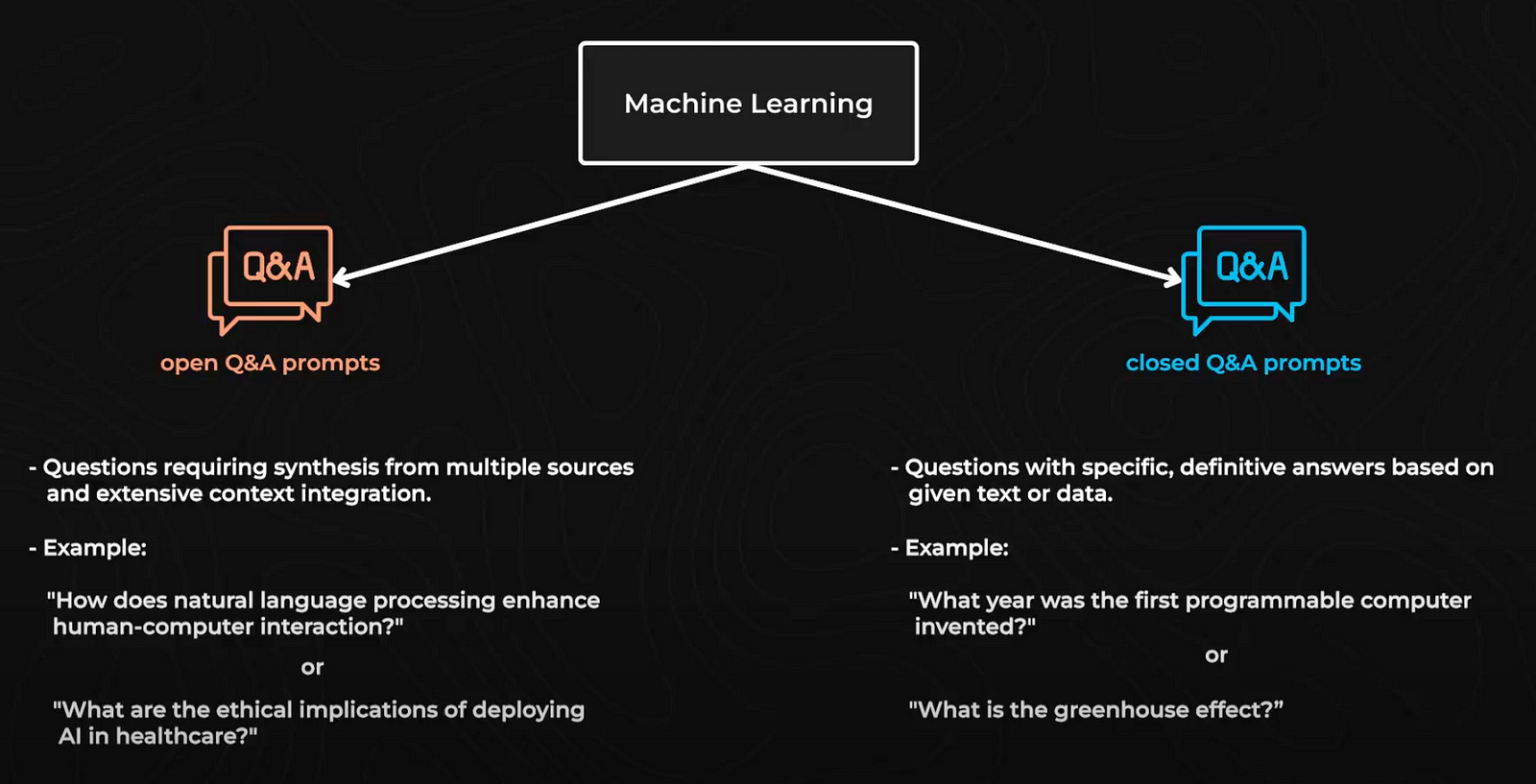
There are two types of questions: open Q&A prompts and closed Q&A prompts. Open Q&A prompts involve questions that require a response generated from understanding and integrating information from a large context or multiple sources, such as “How does natural language processing enhance human-computer interaction?” or “What are the ethical implications of deploying AI in healthcare?” Closed Q&A prompts, on the other hand, involve questions that have specific, definitive answers that can usually be directly retrieved from a given text or dataset, such as “What year was the first programmable computer invented?” or “What is the greenhouse effect?”
For open Q&A prompts, the generated questions are refined to make them more specific and detailed. For example, a general question like “What are the applications of machine learning?” might be refined to “How is machine learning used to improve the accuracy of weather forecasts?”
For closed Q&A prompts, they used the C4 dataset, a continuously updated web data collection. Each document from this dataset is fed into the generator, which produces an instruction specific to that document. The document is then concatenated with the instructions using specific manual templates. For example, for a document about machine learning, the instruction might be, “Summarize supervised learning and describe how decision trees are used in the real world.”
Apart from single-turn prompts, the model needs data on how to follow specific instructions and how to answer in a way that meets the user’s requirements. This brings us to the next two important types of prompts: instruction-following prompts and preference data. Let’s look at them one by one and explain why these were useful for diversity in training data.
What is instruction-following? It is when the model understands and executes specific instructions a user gives, ensuring the model aligns with the user’s expectations. In Nemetron’s case, its own generator, or the current best model, creates these instruction-following prompts, each paired with a general prompt. For example, if the general prompt is “Write an essay about machine learning,” the instruction prompt might be “Your response should include three paragraphs,” assuming the answer in our dataset has 3 paragraphs, obviously. This pairing helps the model deliver responses that meet specific user requirements automatically. Here, an interesting variation is multi-turn instructions, where the instruction applies to all future conversations. For example, if the multi-turn instruction is “Answer all questions with detailed explanations and examples,” and the user first asks, “What is the significance of the Turing Test?” the model would provide a detailed explanation, including examples. If the next question is “How does the Turing Test apply to modern AI?” the model would continue to follow the instructions and provide a similarly detailed response with examples. So, in this case, it makes the model keep the same style of explanation.
Now for the third technique, preference data. Preference data involves synthetically creating two-turn prompts to help the model learn and adapt to user preferences more effectively. For instance, we use a user prompt from ShareGPT, a platform where users share their interactions with AI models. Let’s say the user prompt from ShareGPT is, “What is the meaning of life? Explain it in 5 paragraphs.” The model then generates the assistant’s response: “The meaning of life is a philosophical question that has been debated throughout history. It is a complex and multifaceted topic, and different people may have different answers.” Based on this response, another reply is generated and labeled as the user’s response, such as “Shouldn’t the answer be 42?” This cycle helps the model learn to anticipate and respond to user preferences. Even if this one might not be that accurate, but surely adds meme potential to the LLM. To ensure that the responses differ from one another and maintain a realistic dialogue, the model is given clear role descriptions on how to provide answers when replying as either the assistant or the user. For example, as the assistant, the model might be instructed to provide detailed, informative answers, while as the user, it might ask follow-up questions that seek further clarification or additional information.
We’ve discussed single and two-turn conversations with the model, but in real life, our conversations with the model usually go back and forth multiple times. To handle these longer interactions, we use a method called synthetic multi-turn dialogue generation. Here, we assign the model two roles: one as the assistant and one as the user. The model receives specific instructions for each role and starts with an initial prompt, such as a question or statement. It then alternates between these roles, creating responses back and forth, simulating a real conversation. This process helps the model learn to manage extended dialogues by practicing both sides of the interaction. However, this approach is risky as it can enter boring repetitive loops and return to our initial data diversity problem.
From all these prompting techniques, the next step is to ensure that the model delivers the correct response in the way the user wants and stays diverse. This is called preference fine-tuning and is based on the correctness of the response. To generate this, we need a prompt and its associated correct and incorrect response. For example, if the prompt is “Explain the process of photosynthesis,” a correct response would accurately describe the stages of photosynthesis, while an incorrect response might provide unrelated or incorrect information.
If you remember, different prompts have been given to multiple intermediate models that generate responses to train the next model. Using multiple models creates a more challenging synthetic dataset. This helps ensure the diversity of the data, as each model may generate slightly different responses to the same prompt, reflecting a broader range of perspectives and styles. We can use ground truth labels or a model to determine if the responses are correct. Ground truth can be based on existing dataset labels or validated using tools for Python or mathematical tasks. For instance, for a prompt related to solving a math problem, the ground truth label would be the correct answer calculated by a verifier. We could use an LLM or a reward model as a judge for model evaluation. For example, if we use an LLM, we generate responses from two different intermediate models and compare them. To avoid positional bias, we swap their positions and compare the responses again. It was observed that reward models perform better than LLMs as judges by differentiating the responses more accurately. For instance, the reward model used here, Nemotron-4–340B-Reward, shows higher accuracy in evaluating responses in complex scenarios, such as distinguishing between nuanced and straightforward answers to technical questions. This approach not only ensures the correctness of responses but also maintains a diverse set of high-quality training data, enriching the model’s ability to handle a variety of queries and instructions.
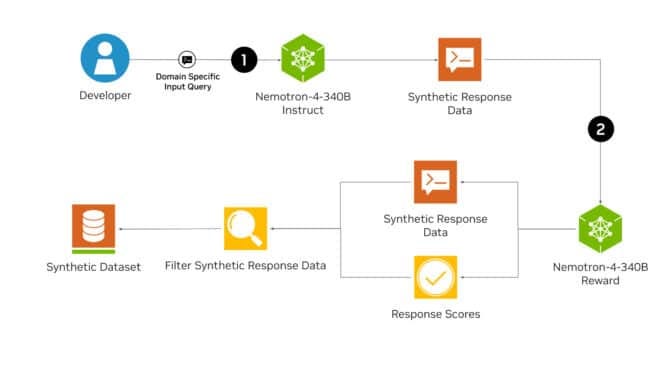
Tl;dr: We can see how important more advanced prompting techniques are, especially as we are building increasingly integrated systems interdependent on autonomous LLMs working together.
Synthetic data training offers a promising approach to developing models that are not constrained by data bias, quality issues, or high costs. I hope this overview into how data can be generated for custom domains and how Nvidia has done it with their Nemotron family of models. If you’re interested in learning more about how LLMs are used in real-world applications and their broader impact, be sure to subscribe to the channel and check out our new book, Building LLMs for Production, where we discuss this crucial step in depth with practical examples.
Thank you for watching, and I will see you in the next one!