OpenAI's o1 Model: The Future of Reasoning AI? What Sets It Apart
How OpenAI's o1 Model Thinks Through Problems (And Why It's Slower)


Watch the video!
Good morning everyone! This is Louis-Francois, CTO and co-founder of Towards AI and today, we’re diving into OpenAI’s latest model, o1, which has some exciting new features that set it apart from previous models like GPT-4o, GPT-4, and even models like Claude, Gemini, and LLaMA. So, let’s break down what o1 does differently, how it works, and what makes it both powerful and, well... a bit slow. But we’ll get to that!
What is o1 and How Does It Work?
So, what is o1? OpenAI’s o1 model is their latest iteration focused on advanced reasoning and chain-of-thought processing. Unlike previous models like GPT-4o or GPT-4, o1 is specifically designed to “think” before responding, meaning it doesn’t just generate text but goes through multiple steps of reasoning to solve complex problems before responding. This approach makes it better at tasks that require detailed reasoning, like solving math problems or coding challenges. It’s pretty much like us, thinking before we speak.
Unfortunately, as with some of us, this process of thinking before answering makes o1 much, much slower than previous models. Sometimes even causing no responses.
When you ask a question, it takes a longer because it’s spending more compute on inference—basically, it’s taking the time to reflect and refine its response. Just as we would ask to “think through it step by step” with Chain-of-Thought prompting, but it does that every time because of how they further trained the model with reinforcement learning to force it to think step by step each time and reflect back before answering. Unfortunately, there is no detail on the dataset used for that other than that it is “in a highly data-efficient training process.”
While the results seem impressive, we will have to wait to see if people like the fact that it takes much longer to get good results. Still, there are some very interesting things to mention…
Key Differences Between o1 and GPT-4o
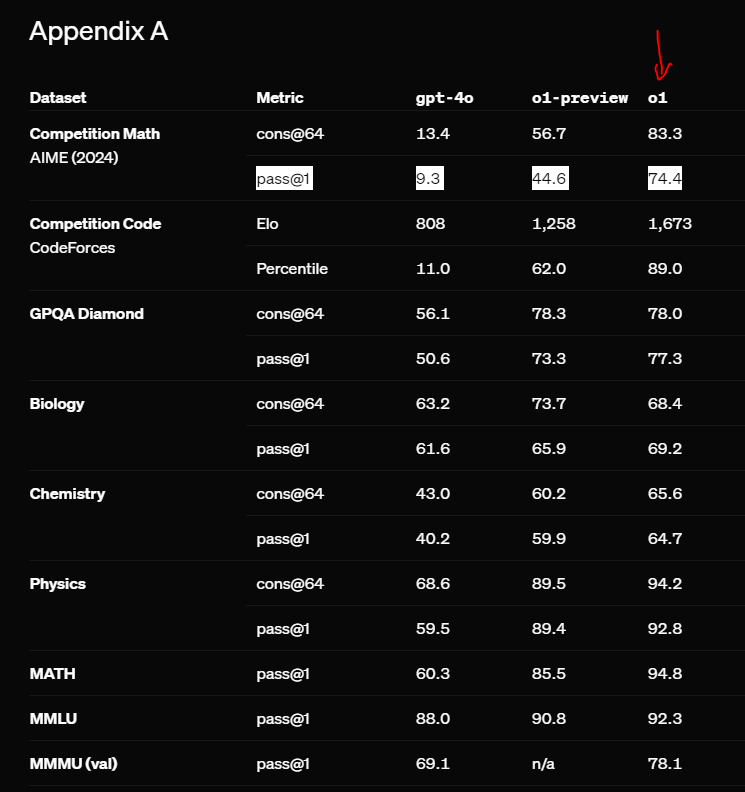
First, what really sets o1 apart from models like GPT-4o is obviously its built-in reasoning capabilities. In testing, o1 outperformed GPT-4o on reasoning-heavy tasks like coding, problem-solving, and academic benchmarks. One of the standout features of o1 is its ability to chain thoughts together, which means it’s better equipped to tackle multi-step problems where earlier models might have struggled.
For example, in tasks like math competitions and programming challenges, o1 was able to solve significantly more complex problems. On average, o1 scored much higher on benchmarks like the AIME (American Invitational Mathematics Examination), where it solved 74% of the problems, compared to GPT-4o’s 9%.
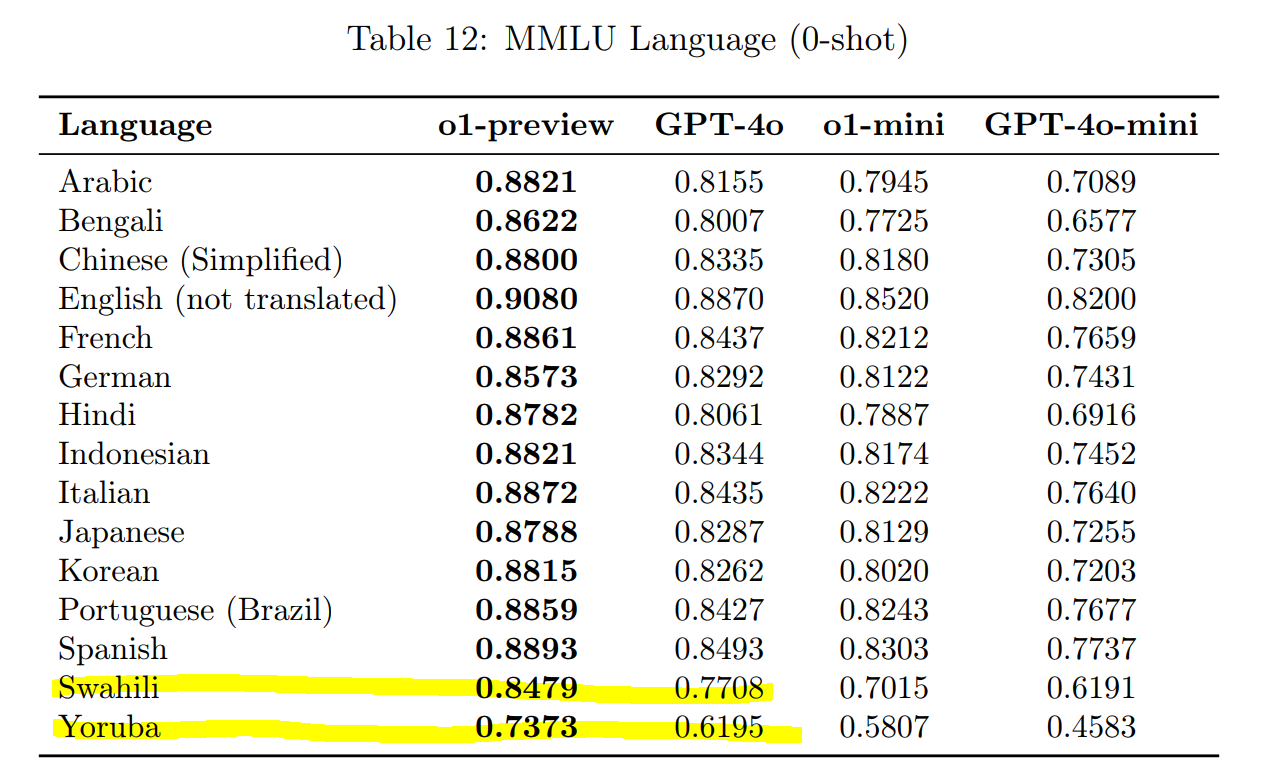
It also does a great job handling multilingual tasks. In fact, in tests involving languages like Yoruba and Swahili, which are notoriously difficult for earlier models, o1 managed to outperform GPT-4o across the board.
Inference Time and Performance Trade-Off
Here’s where o1’s strengths turn into its potential weakness. While the model is much better at reasoning, that comes at the cost of inference time and the number of tokens. The chain-of-thought reasoning process means that o1 is slower than GPT-4o because it spends more time thinking through problems during inference, so when it talks with you, instead of focusing on using high computes strictly for training the model. It’s pretty cool to see another avenue being explored here, improving the results by a lot, and now viable thanks to the efficiency gains in token generation from recent models continuously reducing generation prices and latency. Still, it increases both significantly.
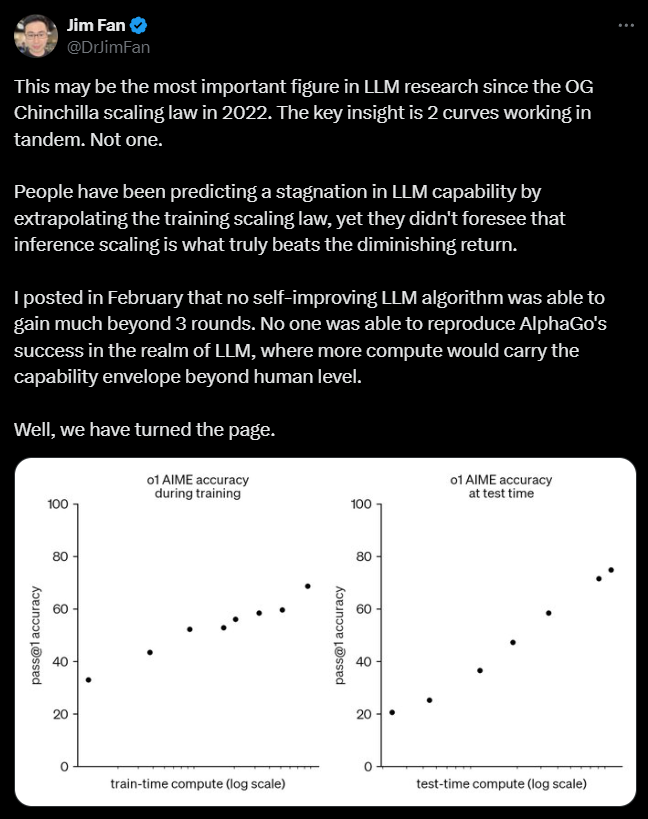
This latency difference is especially noticeable in tasks where the model is expected to handle complex, multi-step reasoning. So, if you’re using o1 for quick, straightforward tasks, it might feel a bit sluggish compared to models like GPT-4o-mini or Claude. It’s essentially the trade-off between speed and depth of understanding.
Hallucination Reduction
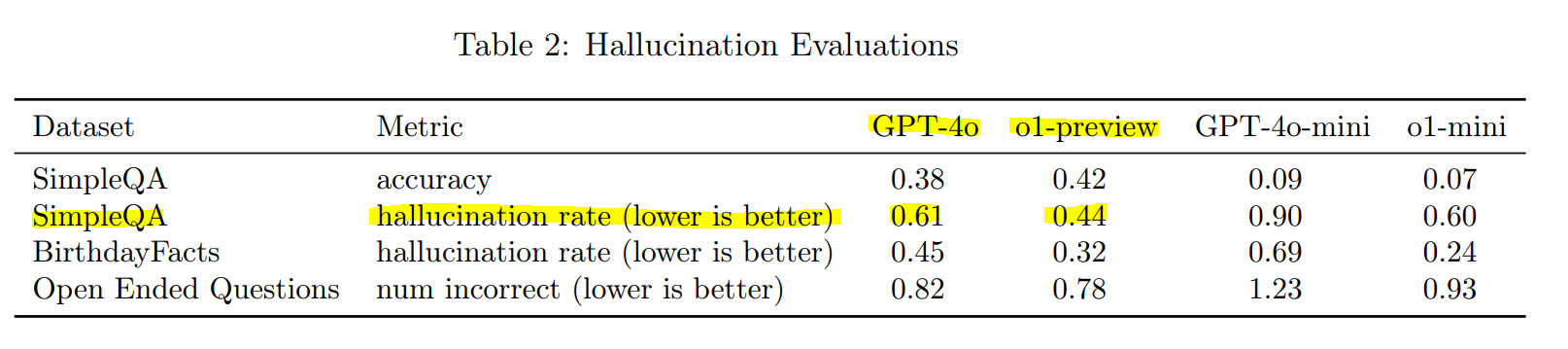
Another area where o1 shines is reducing hallucinations—those moments when the model just makes stuff up. During testing, o1 hallucinated far less than GPT-4o, particularly on tasks where factual accuracy is critical. For example, in the SimpleQA test, o1 had a hallucination rate of just 0.44, compared to GPT-4o’s 0.61. This makes o1 more reliable for tasks where getting the facts right is essential.
Self-Reflection and the "Strawberry Problem"
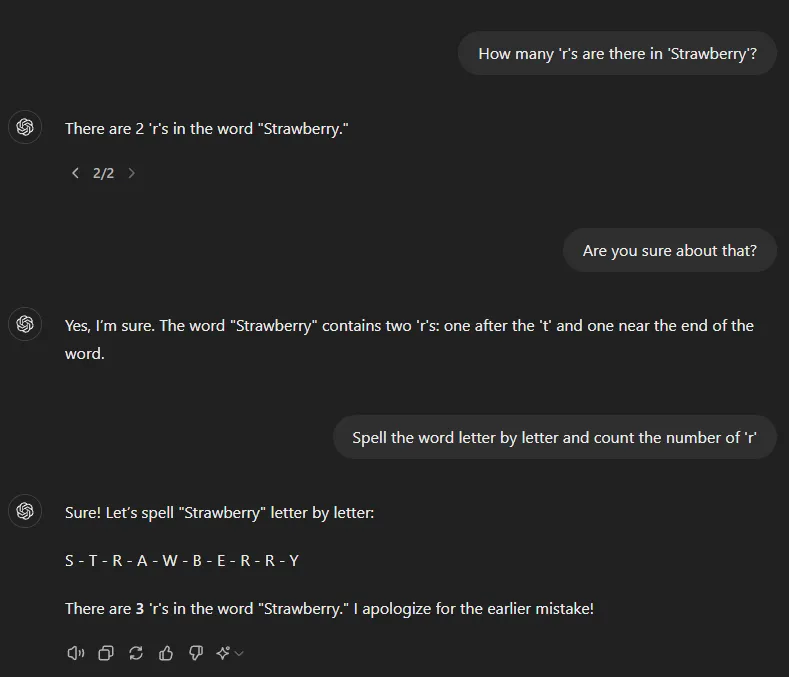
You might have heard people referring to something called the “Strawberry Model,” which is actually a codename for o1 in some circles. The reason it’s called “Strawberry” is a bit of an inside joke—because of the number of "R’s" in the word ‘strawberry’, which kind of ties into the idea of complex reasoning. Just like how it’s tricky to count the R’s in ‘strawberry’ for a model, it’s tricky to get the right reasoning steps every time, but o1 makes this process much more efficient.
Fairness and Bias HandlingAnother major upgrade in o1 is how it handles fairness and bias. In fairness evaluations like the BBQ test, o1 was much better at avoiding stereotypical responses compared to GPT-4o. However, it’s not perfect—when faced with ambiguous questions, o1 sometimes struggles, especially when the right answer should be "Unknown." But overall, it’s more aligned to human values, particularly when compared to GPT-4o.
Final Thoughts on o1So, OpenAI’s new Strawberry, or the o1 model, isn’t such a big leap forward. It’s basically just a better model implementing the chain-of-thought prompting most of us already were using, and it has been done before. The issue is that it took longer to generate and cost more through higher token usage, so people stopped doing it. It seems like OpenAI decided otherwise and went all in on this. Indeed, it’s slower than models like GPT-4o because it takes time to think through problems, but if you need a model that excels at solving complex tasks, o1 is your go-to choice.
If you're working with complicated problems or need a model that's reliable across different languages, o1 is definitely worth the extra wait time. But if speed is your priority, GPT-4o-mini might still be the better option.
As always, I’ve linked more detailed resources in the description below and a really cool livestream from David Shapiro if you want to dive deeper into how o1 works and its results.

I usually try to explain research papers or approaches, but unfortunately, OpenAI didn’t say much about the reinforcement learning process or the data they used, as usual. Still, we can assume the model must be very similar to GPT-4o and the dataset just a well-curated dataset implementing chain-of-thought processes.
I hope you found this short article useful anyway, demystifying what o1 represents compared to the current best LLMs. Thanks for reading, and I’ll see you in the next one!
Extra Ressources:
OpenAI release blog: https://openai.com/index/introducing-openai-o1-preview/
OpenAI release blog 2: https://openai.com/index/learning-to-reason-with-llms/
OpenAI system card: https://openai.com/index/openai-o1-system-card/
Nathan Lambert’s great article on it: https://www.interconnects.ai/p/openai-strawberry-and-inference-scaling-laws
David Shapiro fun livestream testing it: https://youtu.be/AO7mXa8BUWk