Google’s New AI Robot Can See and Understands Language! (PaLM-E)
Google's New AI Model PaLM-E Explained



Watch the video!
You’ve seen the power of recent image and text AIs like ChatGPT or Midjourney. Those are the most known since they generate things, but what about those that understand the images and text? Isn’t it even more impressive? We’ve seen many of them, like the Vision Transformers or ViT, which are state-of-the-art models in understanding images, and the same kind of models like the Pathways language model, PaLM, for understanding text. Basically, large AI models that are able to see an image or sentence and understand what it means.

Imagine what happens when you merge both text and image models. You get an AI able to understand images and text, which means it understands pretty much anything. What can you do with that? At first sight, not much since it can just understand things, but what if you also combine those with something that can move in the world like a trained robot? You get PaLM-E!

PaLM-E, Google’s most recent publication, is what they call an embodied multimodal language model. What does this mean? It means that it is a model that can understand various types of data, such as text and images from the ViT and PaLM models we mentioned, and is able to turn these insights into actions from a robotics hand, like this…
In the video (or their website), we have access to examples including one with the command in the form of text saying, “bring me the rice chips from the drawer”. From that, the robot directly knows where to go and what to do. So it understands its environment thanks to the vision model using its cameras and the command thanks to the PaLM language model part. It even understands what happens if there are unpredicted changes, like someone trolling it and moving stuff around while it works, which we know always happens when we go for a bag of chips.

How cool is that?! Just look at how well it understands situations where we give it an image and some text. Its understanding is shown here in orange… They actually used the coolest research in all three fields, vision, language, and robotics, and turned them into something applicable and useful. Just like ChatGPT makes language AI useful to lots of people, this new research allows for the development of pretty useful robotic help by correctly understanding lots of dynamic situations and transforming it into applicable step-by-step instructions it can follow or adapt from.
All this is thanks to a single model. PaLM-E is basically all based on a single large language model. In this case, it’s Google’s PaLM model. This model allows it to understand and generate text. It’s basically the same as GPT models that you most certainly know about, or else you should watch my video about one of them, like ChatGPT, to have a better understanding of how it works. By the way, it’s also why the model is called PaLM-E, since it uses the PaLM initial architecture and makes it embodied, meaning that it gives “a body” to it. Since this PaLM model is already super powerful to understand and interact with the world in a textual format, the only thing we need to do is to make it see, and then make it act. How do we do that?
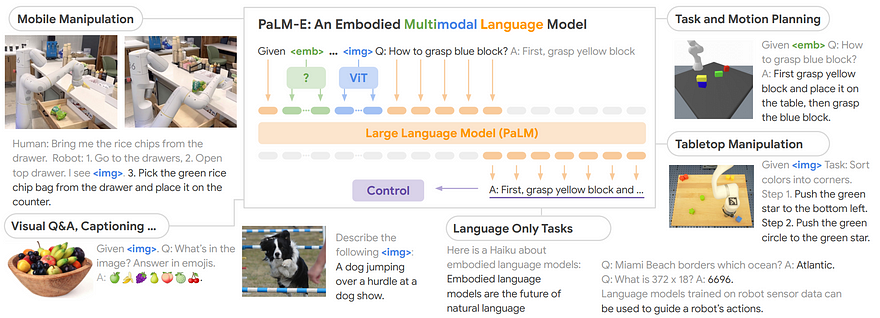
By adding more AIs into it! To make it see, we add more modalities. This means more input data types like images or the state of the robot or agent into the initial text sentence we send, which will help it move and act in the real world. The input will thus be just a blend of images, text, and other sensory inputs the robot has access to.
This is the robotics part of the algorithm and what allows it to wander around and react to the trolling person here because it has access to live information and updates its decisions.
The vision part is relatively easy. You take the image or camera feed and use another AI to transform this image data into something that the model can understand, which we call embeddings. Here we use one of the most powerful vision models called ViT, which is a transformer-based model for vision with an architecture similar to the GPT models but made for images instead of text. This will allow the model to translate an image into a new representation that is the same as the one used for the text. Meaning that, for the model, an image will be the same as if we had written a caption for it. We do the same thing for the robot’s current state to tell it what’s it currently doing so it better knows what the next step should be. All data is transformed into the same space as the text so that we can use the language model alone to process everything at once.
Before diving into the second step, I just wanted to take a second to advertise my new Podcast, where I will interview people in the field to cover very interesting topics like the upcoming episode with a self-driving car expert or the past episodes we’ve had with a Kaggle quadruple grandmaster, a senior data scientist at NVIDIA or the VP of research at a generative startup. These were amazing and super insightful interviews that I am sure you will love. I personally loved doing them and will surely continue. The episodes are all live on Apple podcast and Spotify under the same name, What’s AI by Louis Bouchard. That’s it. Let’s get back to it!
Then, we only need something to make it act, or, as they say, to control the agent. Here, since we have a powerful already trained language model similar to GPT, we can already ask it what it should do, and based on what it sees and its current positioning, it should be able to formulate a logical answer.
There are two steps left to have such a general robot able to understand us and do as we wish:
- We need to do is ask it the right questions to get the desired answers.
- We need to act upon those desired answers and not just say them and not do anything as with ChatGPT.
The first step is all up to the user, so that’s relatively easy to do if you are good at talking with AIs, which we now call a prompt engineer. If you’d like to learn more about that, I invite you to watch my video explaining what prompting is and how to better talk with AIs!
The second step is harder. How do we decide what to do? The model has access to the question we asked it as well as all the images and observations it can make. It has access to so much information that making a decision is no longer a challenge. For example, if you want it to do something, you just need to add to the question something like “respond with the sequence of actions to do the task”. As you know, it will easily be able to list all the required steps, just like ChatGPT would. Now, how do you act on those steps? Based on what the robot has done during training in similar conditions and tasks, it needs to figure out what to do next. As long as the steps are very simple and easy to follow, there should be no issue, and you can just ask the model to generate such simple numerous tasks. The simpler it is, the fewer chances we have for our robot to fail at a task, so just divide a complicated task into a series of small steps. Then, take each of these steps and do the right movements to accomplish them, just like most reinforcement learning-based robots or algorithms you’ve seen in the same way AIs win chess games, one move at a time.
What is really cool is that this architecture also allows them to train the model on many different tasks at the same time, which we previously required a unique algorithm for each, and has proven to improve the abilities of the robot at all tasks by training on more examples, even if unrelated. As always, more data is key!
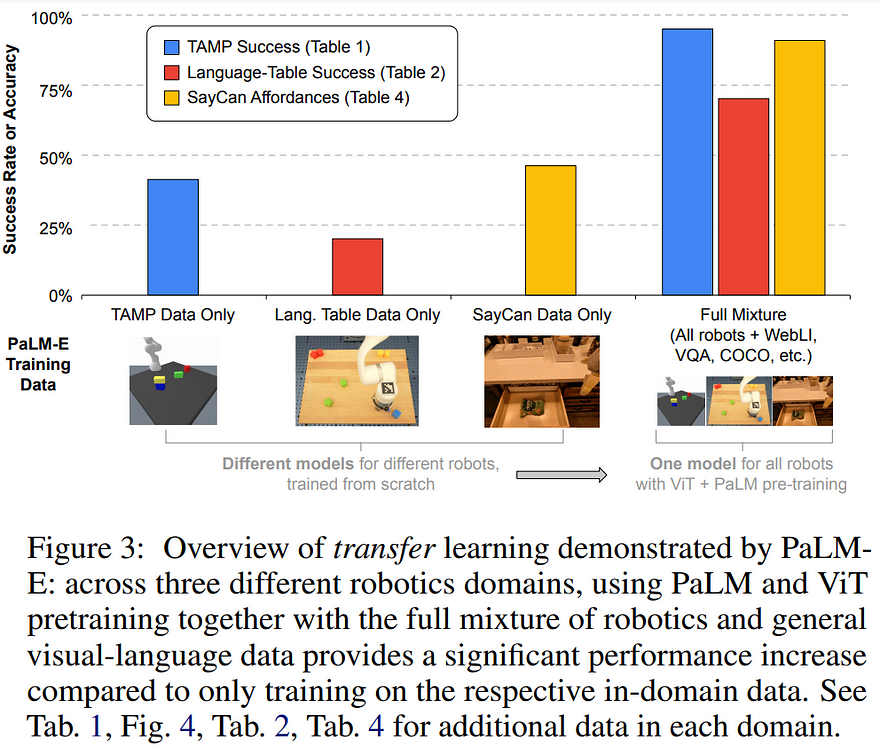
They also observed that the bigger the model is, the most general it becomes (here below shown in blue), which makes sense since you are just allowing it to retain more information.
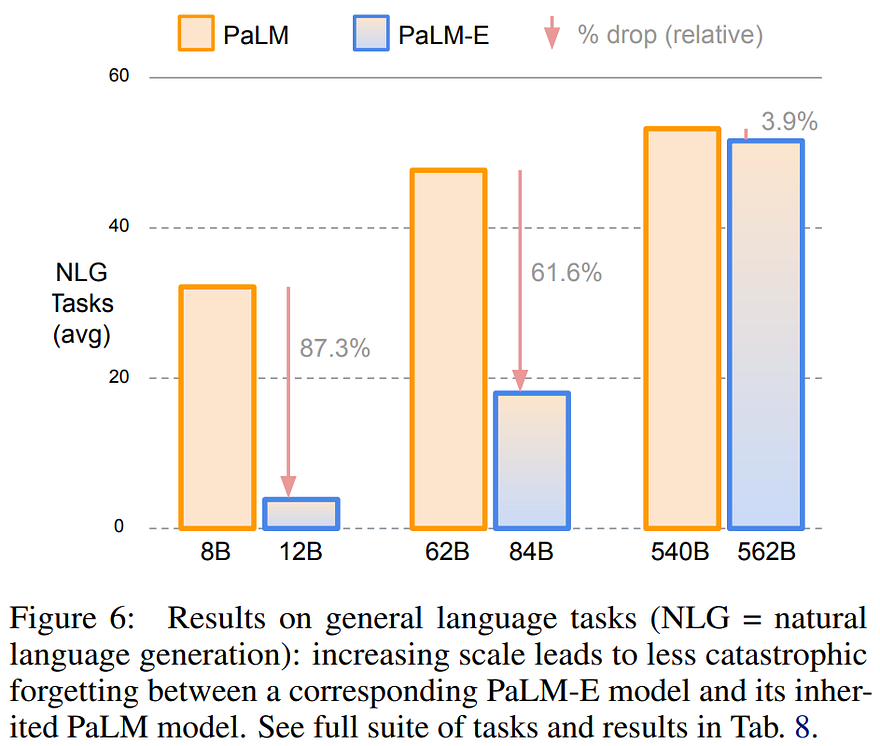
This shows how scaling larger models with more data seems to always improve the results. But the coolest part is that it doesn’t require specifically the same type of data or even the same task to be trained on. It can improve its visual capacity by training on more text. More, it improves on a task by training on another, which also makes perfect sense. Just like humans training for a spring; obviously, doing sprints is ideal; but doing longer distances as well as strength workouts in the gym will also work, improving your sprinting ability. Likewise, watching yourself or other sprinters on TV will allow your brain to practice sprinting even though you are not actually doing anything physical. It’s really cool how PaLM-E basically implements all those human ways of learning to make a better algorithm. Quite exciting and promising!
Of course, this was just an overview of the PaLM-E model, and I invite you to read their great paper to learn more about how it works and why it’s such a great step forward. I hope you’ve enjoyed this article, and I will see you next time with another amazing paper!
References
- Driess et al., 2023, Google: PaLM-E, https://palm-e.github.io/assets/palm-e.pdf
- See more examples: https://palm-e.github.io/#demo
- Link to my new podcast (with an RTX 4080 giveaway running now!): https://podcasters.spotify.com/pod/show/louis-bouchard