Mastering Prompts: How to Effectively Communicate with AI Language Models
Exploring the unique behaviors of different Large Language Models (LLMs) and mastering advanced prompting techniques!


Watch the video!
Large language models are quite different from each other. From how they understand the world to how you use it, they will react differently, which means different prompts affect the models differently. Let’s dive into the differences between models and better ways of prompting them with a new, very cool approach that came out a few days ago!
Why do different models like GPT-4, Llama-2, or Claude react differently depending on the prompt sent? This is because they understand the world differently using different tokenizers and data. This is just like me versus my friend Omar. To me, a cat is either “a cat” in English or “un chat” in French. But to him, it could also be “gato” in Spanish. Our different languages are basically our tokenizers. It saves the topics, concepts, words, and sentences in a specific format in our brain for us to understand, compare, and retrieve information. It is the same for LLMs. Tokens are their own languages, and we have to translate our human language, like English, into something they understand, which are basically vectors full of numbers that they can then understand and compare.
This is how a model usually sees a sentence… It splits the words, and each of them has an assigned number to it. This number is simply their index in a large dictionary of all English words.
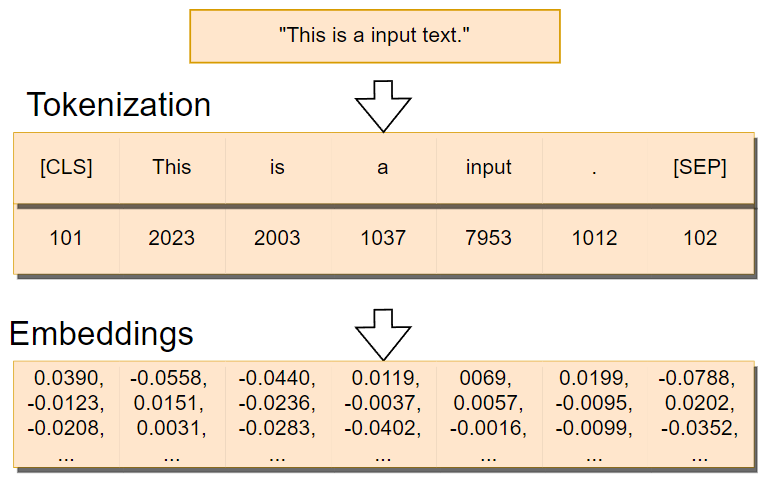
The thing is, different language models use different tokenizers, which already makes a difference in understanding our sentences.
Here’s a quick example to demonstrate the difference between the tokenizers used in three language models: llama, BERT, and GPT-2. I put in some text as well as some simple math, a smiley, an emoji, capitalization and some spaces just to show the different behaviors of the tokenizers. I also show the indices in the word dictionary the tokenizers are using, and we see the index is also different even for the same token. And indeed, look at how different the results are. Note that the special G character for GPT-2 and the underlined llama are just representing spaces. Still, you clearly see that some tokenizers take into account the spaces while others do not, split the words differently into tokens, keep the double equal boolean comparison or not, see capitalizations or skip it, etc. All different behaviors that will surely affect the model’s understanding. Just imagine you want your model to understand when someone is excited or mad, but you cannot see emojis or all caps! This is how we express our emotions when chatting!
Here are some of the examples for the sentence "If you are enjoying the video..." from my Google Colab Tokenizer example:
GPT-2 Tokens:
['If', 'Ġyou', 'Ġare', 'Ġenjoying', 'Ġthe', 'Ġvideo', '...']
GPT-2 Token IDs:
[1532, 345, 389, 13226, 262, 2008, 986]
BERT Tokens:
['if', 'you', 'are', 'enjoying', 'the', 'video', '.', '.', '.']
BERT Token IDs:
[2065, 2017, 2024, 9107, 1996, 2678, 1012, 1012, 1012]
Llama Tokens:
['▁If', '▁you', '▁are', '▁enjo', 'ying', '▁the', '▁video', '...']
Llama Token IDs:
[960, 366, 526, 11418, 5414, 278, 4863, 856]
Another example with the sentence and spaces in ", give it a thumbs up and SUBSCRIBE!":
GPT-2 Tokens:
[',', 'Ġgive', 'Ġit', 'Ġa', 'Ġ', 'Ġ', 'Ġthumbs', 'Ġup', 'Ġand', 'Ġ', 'Ġ', 'Ġ', 'ĠSU', 'BS', 'C', 'RI', 'BE', '!']
GPT-2 Token IDs:
[11, 1577, 340, 257, 220, 220, 32766, 510, 290, 220, 220, 220, 13558, 4462, 34, 7112, 12473, 0]
BERT Tokens:
[',', 'give', 'it', 'a', 'thumbs', 'up', 'and', 'sub', '##scribe', '!']
BERT Token IDs:
[1010, 2507, 2009, 1037, 16784, 2039, 1998, 4942, 29234, 999]
Llama Tokens:
['▁,', '▁give', '▁it', '▁a', '▁▁', '▁thumb', 's', '▁up', '▁and', '▁▁▁', '▁SUB', 'SC', 'RI', 'BE', '!']
Llama Token IDs:
[1919, 2367, 372, 263, 259, 28968, 29879, 701, 322, 1678, 27092, 7187, 3960, 15349, 29991]
And here's a last example with the string:
"""2 + 2 == 2*2 \t :)
💃
"""
GPT-2 Tokens:
['2', 'Ġ+', 'Ġ2', 'Ġ==', 'Ġ2', '*', '2', 'Ġ', 'ĉ', 'Ġ', 'Ġ', 'Ġ', 'Ġ:)', 'Ċ', 'Ġ', 'Ġ', 'Ġ', 'Ġ', 'Ġ', 'ĠðŁ', 'Ĵ', 'ĥ', 'ĊĊ']
GPT-2 Token IDs:
[17, 1343, 362, 6624, 362, 9, 17, 220, 197, 220, 220, 220, 14373, 198, 220, 220, 220, 220, 220, 12520, 240, 225, 628]
BERT Tokens:
['2', '+', '2', '=', '=', '2', '*', '2', ':', ')', '[UNK]']
BERT Token IDs:
[1016, 1009, 1016, 1027, 1027, 1016, 1008, 1016, 1024, 1007, 100]
Llama Tokens:
['▁', '2', '▁+', '▁', '2', '▁==', '▁', '2', '*', '2', '▁', '<0x09>', '▁▁▁', '▁:)', '<0x0A>', '▁▁▁▁▁▁', '<0xF0>', '<0x9F>', '<0x92>', '<0x83>', '<0x0A>', '<0x0A>']
Llama Token IDs:
[29871, 29906, 718, 29871, 29906, 1275, 29871, 29906, 29930, 29906, 29871, 12, 1678, 4248, 13, 539, 243, 162, 149, 134, 13, 13]
Then, there’s already how they process the tokens. Once tokenized, each token is converted to a vector using an embedding layer. This means each token is represented as a point in a high-dimensional space. These vectors capture semantic meaning. This is where your model will understand the meaning of those words and especially the more complex structure like a sentence, where each word has relations to each other.
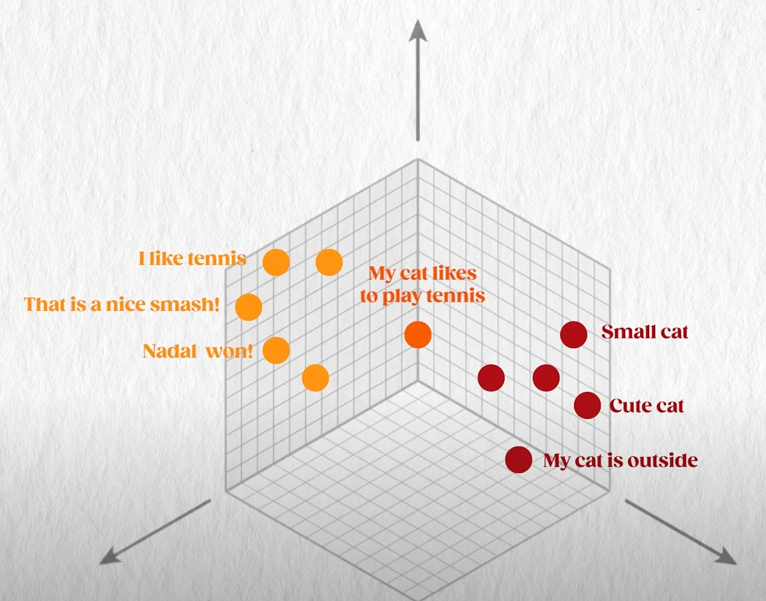
This encoder part is trained along with the model during the self-supervised part, where we basically give it parts of sentences from the whole internet and ask it to guess what happens next. We can make the model train itself because we already have access to the rest of the sentence from the internet, so we just wait and make it understand and digest lots of content this way. If the training process is long enough, the model should construct its own understanding of our world, as GPT-4 did, but it is indeed its own understanding, depending on the tokenizer choice and on this embedder part that we are training for this specific model.
So this is why each LLM is unique and understands our queries differently. It also depends on the data we fed it during training, whether it was more discussion-like, instructions, or anything else for a specific use case we had in mind. The models also have parameters like temperature or penalty parameters that you can play with, affecting how often the model should be using the same tokens or different ones when generating words or also how creative it should be, which you can almost always tune in the different models. All those variables and differences between models are why the secret to being a better prompt engineer is… to practice with the models themselves! You cannot generalize one technique from one model to another. Still, there are techniques that are quite general and can improve your model, and here are a few of them…
First, play with those parameters figuring out what works best for your task. Do you need the model to dumb it down a bit and use simpler and more common words? Do you want it to be creative, or do you want the model to ensure more grammatically correct outputs but that might lack creativity? Once you figure out those needs for your task, keep them in mind and adjust the parameters accordingly to find your best fit with trial and error.
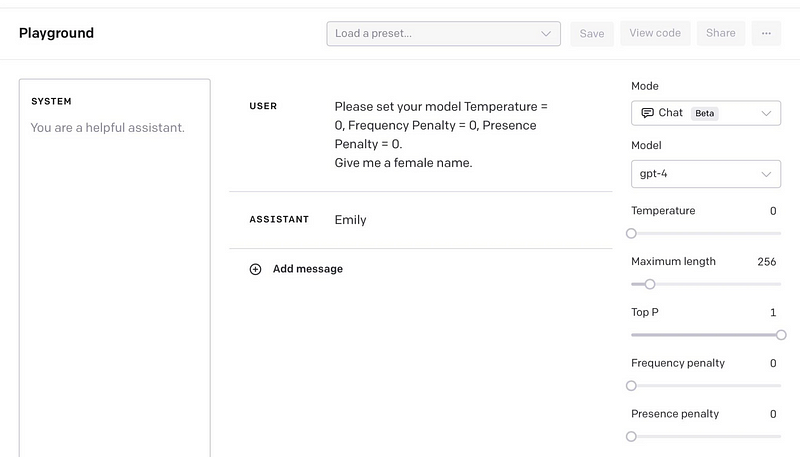
Then, you should jump into prompting while also adapting the parameters if you drastically change your prompts.
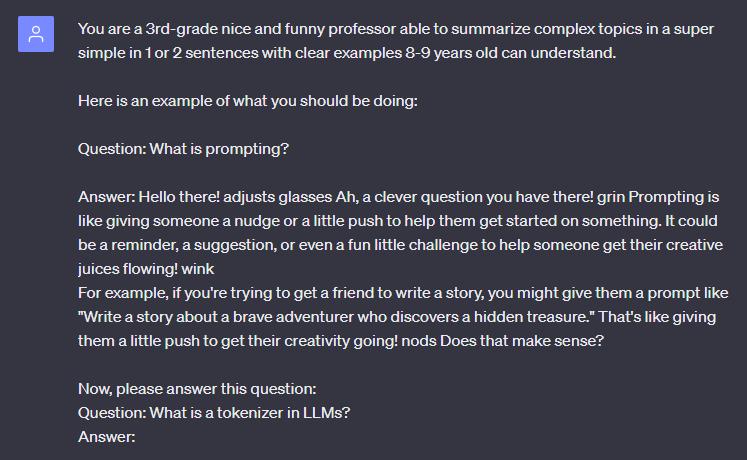
The first thing to do is define a good system prompt. Like the one we had at the beginning of the video, asking it to be a 3rd-grade teacher and make the explanation super digestible. This system prompt, basically giving a role and the task to accomplish to your LLM, is the most important part of the whole process. It’s basically like retraining your model on a specific task, but without actually retraining it, which has lots of cost and time benefits!
Then, think of what you want to do and dive into more advanced prompting techniques. Here, I will list my favorite ones that work pretty much for all cases, but I strongly invite you to consult online resources like learnprompting.org, which lists and explains all the best techniques to control LLMs outputs better.

The best one I could suggest is to use few-shot prompting. This is where you will give an example of what you want to the model and ask it to do the same. This is super powerful if you are building an app for a specific use case, like generating summaries intended for 3rd-graders, for example! And what’s cool about few-shot prompting is that it works super well, even with a single example given!
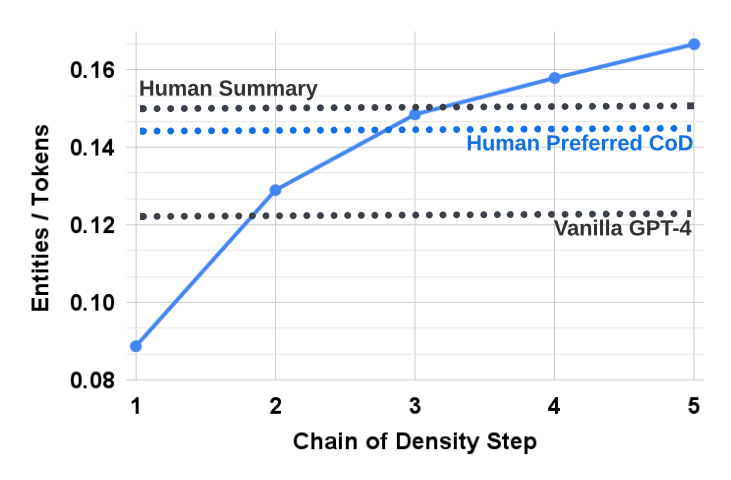
A very cool new method called Chain of Density prompting, or CoD is also quite powerful, especially when dealing with summarization tasks. In this new method, we ask the model, like GPT-4, to provide an initial basic summary and then ask it to repeatedly add more specific details without making the summary longer. It simply repeats two steps a few times, following this prompt you use or a similar one: identify specific details, here called entities, from the article that were not mentioned in the current summary and then re-writing the summary with an identical length, keeping all specific details it already had plus the new ones we just identified. So it has to fit in these new details, improving the summary little by little, changing only parts of the content without adding more and more words, thus making the summary more and more information dense and compact: which improves the quality of a summary! If this approach sounds interesting, I linked the paper by Adams et al. introducing it below, which contains many more details and a large study on summaries. It is a very interesting read!


Another great technique if your application is a bit more complex and requires some thinking to do is called zero-shot chain of thought, where you ask your model to split a complex query into simpler ones by telling it a super simple sentence like “think it step by step”. This is mainly helpful for math or logic-related questions and can be tremendously helpful to improve the results in those cases!
I hope this article could help you better understand that the model, the parameter, and prompt selection are important and also require lots of work and patience and give you a better idea of why that is.
I will see you next time with a very interesting article related to LLMs in the real world, and you don’t want to miss out!
References
- Amazing Prompting resource: learnprompting.org
- Chain of Density Prompting paper from Adams et al., https://arxiv.org/pdf/2309.04269.pdf
- Colab notebook of the tokenizer example: https://colab.research.google.com/drive/1IVQyGmj1t9R12oajT4OMjMWzwZk3jWgm?usp=sharing
- Tokenization in Machine Learning Explained