How to Effectively Evaluate Retrieval-Augmented Generation (RAG) Systems
Why RAG Evaluation Matters and Techniques to Leverage


Watch the video!
You are probably implementing RAG systems, missing out on easy improvements. Most don’t even have an evaluation pipeline. How can they know if it’s optimal or if their system is improving with any changes? This is through evaluation, which is different from evaluating LLMs themselves. Let’s dive into the key evaluation metrics and methods we’ve found useful while developing RAG systems at Towards AI.
RAG combines retrieval mechanisms (as in Google search) with generative models (e.g., GPT-4) to improve response quality and relevance.
As a quick reminder on what RAG is… RAG is simply the process of adding knowledge to an existing LLM into the input prompt. It is most useful for private data or advanced topics the LLM might not have seen during its training. In RAG, the most basic setup is to “inject” additional information along with your prompt so that it can be used to formulate a better answer.
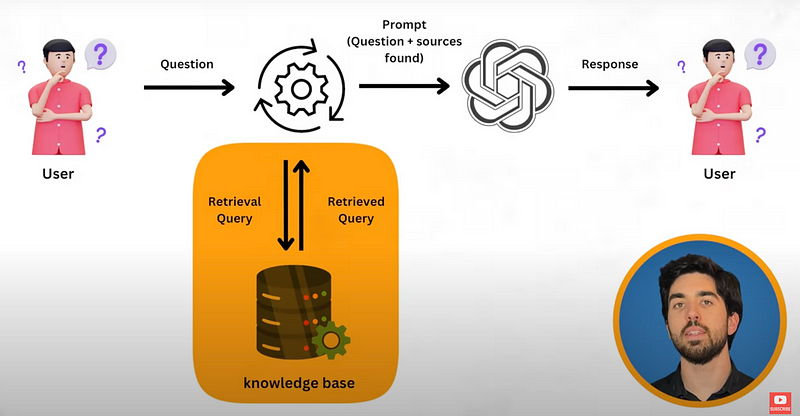
So, why is evaluation important? Effectively evaluating and optimizing LLM-based systems can be the difference between a nice demo and a highly useful, trustworthy LLM tool or product. Whether you’re developing a customer service bot or a research tool, good evaluation will help you create more reliable and effective AI solutions that can actually be shipped to production.
For example, if you are building a legal research tool with RAG, it will need to be contextually appropriate and up-to-date. You can’t just assume it will work fine. You need proper evaluation to ensure a good interpretation of legal jargon and relevant information.
Now, you might think, “I tested the app, and the answers look good!”
While testing the application yourself is very important, you need to play with it yourself, which we call ‘vibe checking’; it doesn’t tell the whole story. We need more rigorous methods and metrics to ensure the LLM applications are performing optimally.
As we’ve said, RAG systems have two distinct components that need evaluation: the retrieval component and the answer generation component.
Let’s discuss how to evaluate both, starting with the most relevant metrics… We’ll discuss the overall pipeline, including the dataset needed for that, in a few minutes.
Retrieval metrics focus on how well the system retrieves relevant information from its knowledge base. So you have your dataset, and you want to find if the system is able to find the most valuable information to answer a user question. Here, you could use four metrics to do that:

- The first is precision. Precision measures the proportion of relevant documents among the retrieved documents. It’s particularly useful when you want to ensure that the information your system retrieves is highly relevant, such as in a medical diagnosis tool where false positives could be dangerous.
- Then, you have recall. Recall measures the proportion of relevant documents that were successfully retrieved. It’s crucial in scenarios where missing important information could be costly, like in legal research where overlooking a relevant precedent could affect the outcome of a case.
- We then have the Hit Rate: Hit Rate measures the proportion of queries for which at least one relevant document is retrieved within the top few results, reflecting the retrieval system’s ability to find relevant documents at all.
- One of the most used is Mean Reciprocal Rank (MRR): This evaluates how high the first relevant document appears in the search results. It’s valuable for systems where users typically focus on the top few results, like in a web search engine.
- Finally, we can use the Normalized Discounted Cumulative Gain (NDCG): This takes into account both the relevance and the ranking of retrieved documents. It’s particularly useful for recommendation systems or any application where the order of results matters.
Here, MRR is useful for evaluating systems where the rank of the first relevant document is most important, such as search engines (e.g. top 1–3 Google results). NDCG provides a more holistic measure of ranking quality, considering the relevance and order of all documents, making it ideal for applications like recommendation systems where the entire list is important (e.g. top 10 lists).
You can then use these five metrics to measure how well your RAG system can find relevant information to send along with the prompt to the LLM. The second step is to evaluate the LLM answer with the generation metrics. We have three main metrics to do that:
- Faithfulness: Faithfulness measures the integrity of the answer concerning the retrieved contexts. It ensures that the generated response accurately reflects the information in the retrieved documents without introducing false or unrelated information.
- Answer Relevancy: It evaluates the relevance of the generated answer to the original query. It helps ensure that the system is not just retrieving relevant documents, but also using that information to generate pertinent responses.
- Answer Correctness: The correctness assesses whether the generated answer aligns with a given query’s reference answer. It’s particularly useful when you have a set of ground truth answers to compare against.
Ok, so that’s cool and all; we have metrics to evaluate our LLM, but then we need a dataset to run them on. An evaluation dataset can be done by leveraging expertise from domain experts, using your own knowledge if you have domain expertise, or even using a powerful LLM to generate complex and contextually rich questions from your indexed data. Remember to review and refine these questions to ensure they reflect real-world usage. You basically want to generate artificial, or ideally real, questions where the answer is in your data. You can then see if the answer provided leverages the right data and gives the expected answer using the metrics we’ve just discussed.
Now, what about the answers? Assuming we’ve got the right information to answer the question, how can we judge if the generation is good? One of the cool new approaches for evaluating the generation is using another LLM as a judge guided by generation metrics. This approach can be highly effective, but it’s important to follow some best practices:
- First, when using an LLM to evaluate outputs, it’s often more effective to have it compare two responses rather than evaluate a single response in isolation. It gives it some sore of baseline to then see if the second response is better. This is called pairwise comparison and usually provides a clearer benchmark for quality.
- But then, when presenting pairs of responses to the LLM judge, you need to randomize the order you give them. LLMs tend to have a bias with order, like always favouring the first option.
- Similarly, you need to allow for ties. It’s possible that two answers are just as good. Give the LLM judge the option to declare responses as equally good. This can provide more nuanced evaluations.
- The best tip is to use a Chain-of-Thought approach, asking the LLM to explain its reasoning before making a final decision. This can lead to more reliable and interpretable evaluations. Since LLMs only generate one token at a time or one word at a time, they don’t think like us. They don’t have some sort of mental map of what they will say and how the response will be structured. They do this on the fly. Asking it to go step by step or even write a plan of action first allows them to have this plan in their context, acting as some sort of artificial thinking before generating the final answer, improving the results and evaluation a lot.
- Our last tip is to try to ensure that responses are similar in length when comparing them. This helps create a fairer comparison, as length can sometimes unfairly influence perceived quality.
By incorporating these LLM-based evaluations alongside traditional retrieval metrics, we can get a more comprehensive view of our RAG system’s performance, addressing both the retrieval and generation aspects. Then, any tweak, feature or prompt can be linked to a quantitative change along with a necessary qualitative check you must always do to check the system’s vibe.
However, these metrics and vibe-checking yourself aren’t enough. We must consider the broader context of how our RAG system is used. This brings us to a critical point that’s often overlooked: the importance of understanding your users’ actual needs.
One of the most effective ways to do this is by logging and analyzing user queries. By implementing a logging system, you can capture every question asked to your RAG system. Then, using techniques like topic clustering, you can analyze these questions to identify common themes and patterns.
For example, we’ve built an LLM application for a client. After analyzing user queries, they finally discovered that 80% of the questions were about a specific subset of topics. This insight allowed them to focus your optimization efforts where they’ll have the most impact. You can tailor your evaluation datasets to these high-frequency topics, ensuring that your system performs exceptionally well on the queries your users care about most. It’s also then much easier to vibe-check than trying to check the whole set of possible questions.
You now have your reason for evaluating, your metrics, and ways to do it automatically, so what’s left? The next step is to implement it.
We suggest using libraries like Ragas to automate and scale your evaluation process. Don’t code everything yourself! These tools can help you measure various aspects of your RAG system’s performance, including both retrieval and generation quality, including all the metrics we’ve mentioned in the article.
Last but not least, don’t forget human evaluation. While automated metrics and LLM-based evaluations are valuable and more scalable, human judgment is still the gold standard, especially for assessing factors like fluency, naturalness of responses, and overall usefulness in real-world scenarios. And as we’ve said, your users are best placed to evaluate this, which can be done through some AB testing or paying people to do that.
You now have the tools to go beyond basic metrics and really understand how well your RAG system is performing in real-world scenarios, focusing on the topics that matter most to your users.
I invite you to check out our course on advanced RAG architectures. In it, we discuss techniques like reranking, query expansion, and lots more to build state-of-the-art RAG systems, from basic implementation to advanced optimization techniques.