OpenAI's NEW Fine-Tuning Method Changes EVERYTHING
Reinforcement Fine-Tuning Explained


Watch the video!
Have you ever wanted to take a language model and make it answer the way you want without needing a mountain of data?
Well, OpenAI’s got something for us: Reinforcement Fine-Tuning, or RFT, and it changes how we customize AI models. Instead of retraining it with feeding examples of what we want and hoping it learns in the classical way, we actually teach it by rewarding correct answers and penalizing wrong ones, just like training a dog — but, you know, with fewer treats and more math.
Let’s break down reinforcement fine-tuning compared to supervised fine-tuning!
Normally, when you fine-tune a model, you give it a bunch of training examples, and it learns to imitate them. This is called supervised fine-tuning, or SFT. It works well, but you usually need a massive dataset for it to be effective. Reinforcement Fine-Tuning (or RFT) flips that, and instead of just copying answers, the model has to figure things out, get feedback, and improve over time. It’s like trial-and-error learning, except the errors get corrected with math instead of frustration. And the best part? OpenAI claims you can get great results with as little as a few dozen high-quality examples. That’s a game-changer.
So why does this matter? Well, the o3 models are super powerful models from their latest “reasoning” series — and they are a perfect fit for RFT. It’s already designed to be great at logical thinking, coding, and math, so applying reinforcement fine-tuning can sharpen those skills for specific domains like legal analysis or financial forecasting. Essentially, instead of having a generalist AI that you want to teach to do math or more complex stuff, where you’d need supervised fine-tuning to learn new concepts, you already have a super powerful model and can just leverage reinforcement fine-tuning to turn it into the expert you need.
Both essentially have their use that we can discuss in one line:
- Supervised fine-tuning teaches new things the model does not know yet, like a new language, which is powerful for small and less “intelligent” models.
- While reinforcement fine-tuning orients the current model to what we really want it to say. It basically “aligns” the model to our needs, but we need an already powerful model. This is why reasoning models are a perfect fit.
I’ve already covered fine-tuning on the channel if you are interested in that. Let’s get into how RFT actually works!
First, you need a dataset — this is your set of tasks or questions, along with the correct answers. Let’s say you want a model that’s great at medical diagnosis. You’d give it a bunch of case descriptions along with the right diagnoses. The key here is that these tasks need to have objective, verifiable answers. If there’s no clear right or wrong answer, RFT doesn’t work as well. So, this is perfect for things like math, coding, and structured decision-making, but not so much for creative writing or opinion-based tasks.
Next, you need a way to grade the model’s answers. This is where things get interesting. The grader is what determines how good or bad an answer is. It can be simple — like a direct comparison to the correct answer — or more complex, like giving partial credit for close answers. Think about a math test: you get full points if your answer is exactly right, maybe half points if you show the correct steps but make a small mistake, and zero points if you just write “42” for everything. Designing a good grader is crucial because it controls the reward signal that drives learning.
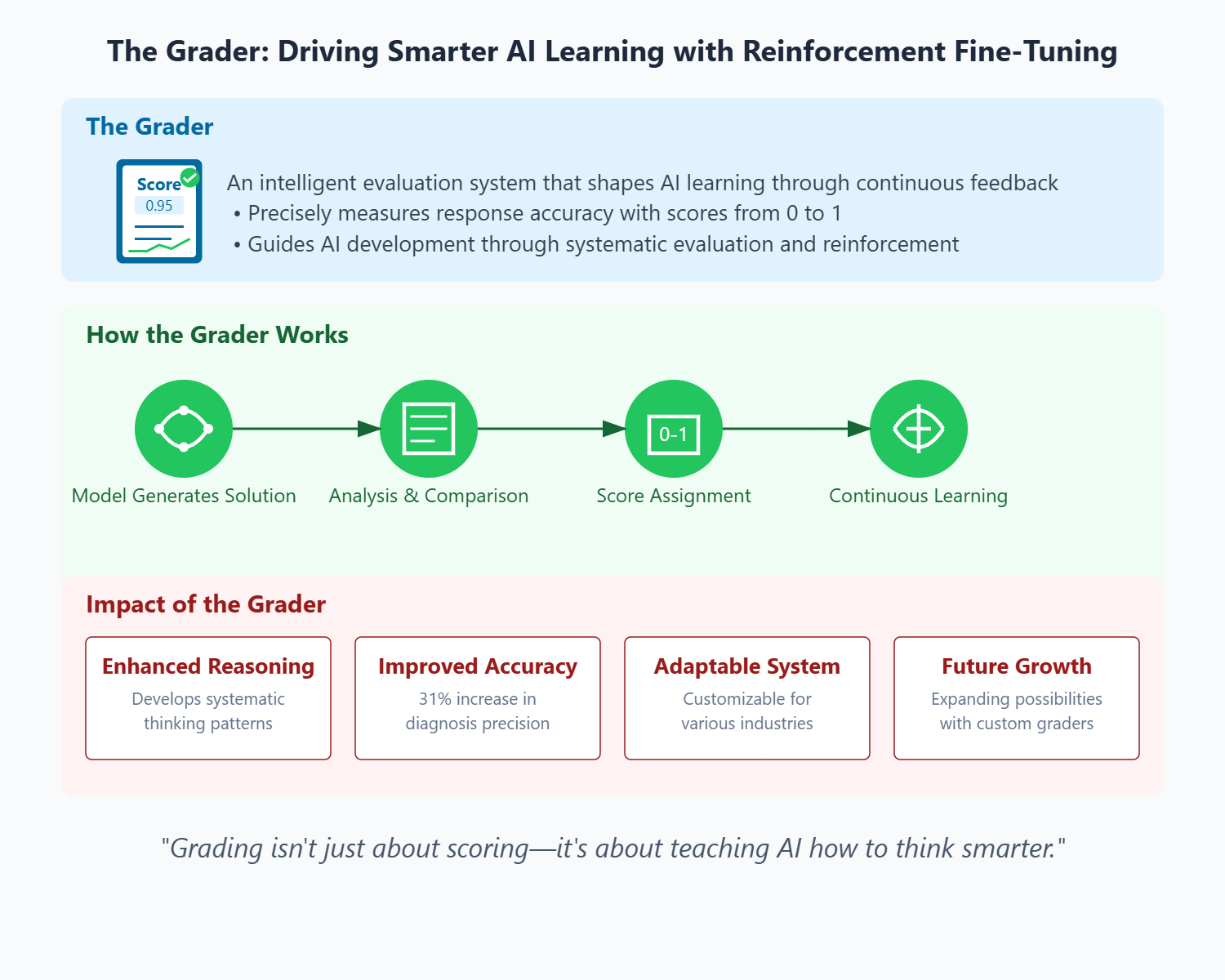
The grading mechanism in Reinforcement Fine-Tuning (RFT) plays a crucial role in shaping how a model learns from its outputs. In RFT, a grader — either a separate model or a predefined heuristic — evaluates the model’s responses against a set of correct answers and assigns scores based on accuracy and relevance. Yep, we can use another language model to score and improve an existing language model! It’s becoming quite crazy! This scoring can be binary (correct or incorrect) or more granular, allowing for partial credit. For instance, a response may receive full credit if the correct answer is ranked first, partial credit if ranked second, or no credit if it is missing. The ability to assign partial credit is particularly valuable, as it enables more nuanced feedback, reinforcing learning even when the model’s response is not perfect. This structured feedback helps stabilize and accelerate training, encouraging incremental improvements over time.
Evaluation metrics are equally important for assessing the performance of models fine-tuned using RFT. Key metrics include top-k accuracy, which evaluates how often the correct answer appears within the top-k predictions made by the model. Specifically, top-1 accuracy measures the percentage of times the correct answer is the first response, while top-5 accuracy assesses how often it appears among the top five responses. Top-max accuracy checks whether the correct answer is included in the output list, regardless of its position. These metrics are tracked over time to monitor improvements, allowing for comparative analysis between different models. Together, the grading mechanism and evaluation metrics provide structured feedback and measurable outcomes that enhance our model’s reasoning capabilities and ensure effective performance in real-world applications.
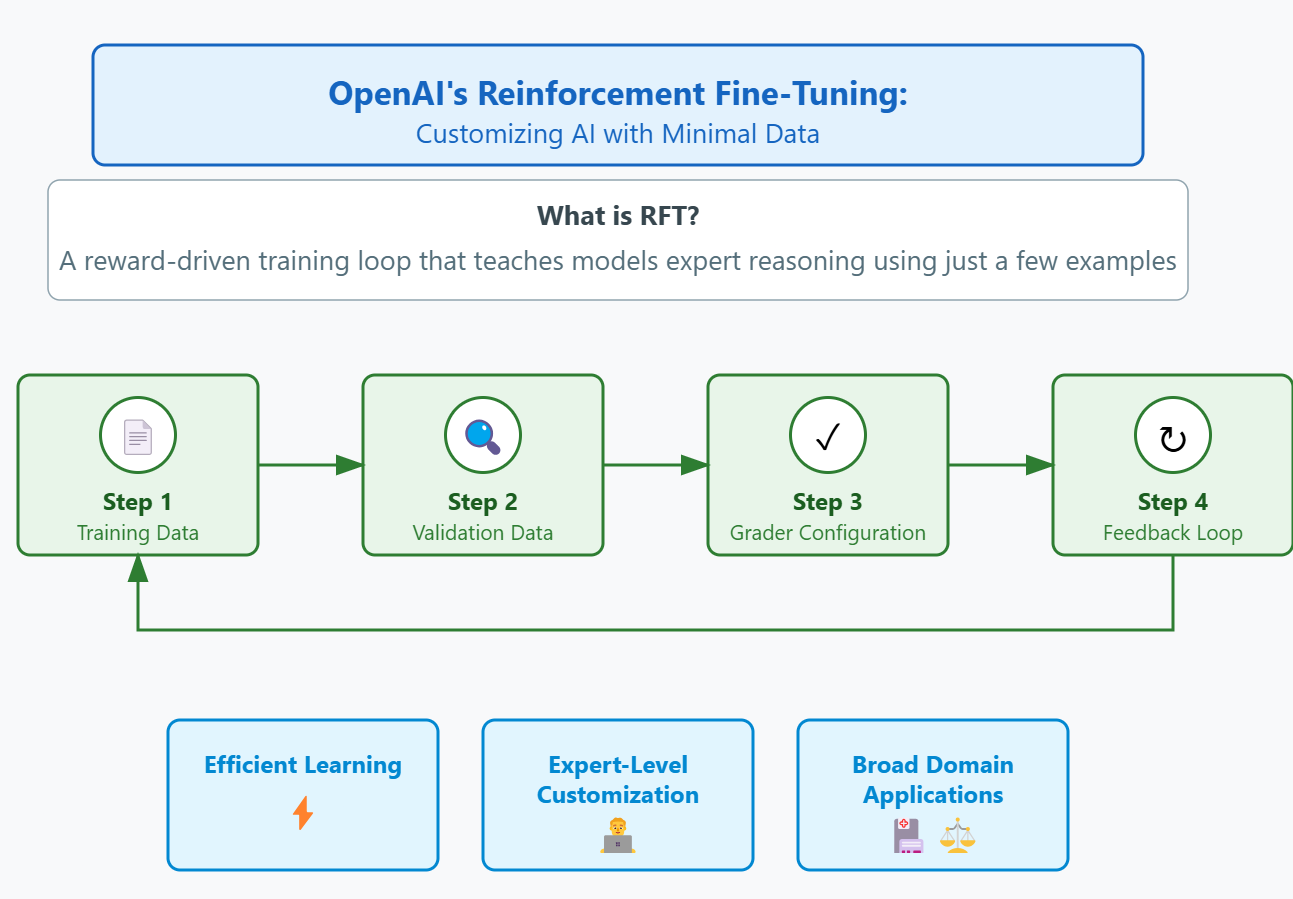
Then comes the training loop. Here’s where the magic happens. The model generates answers, the grader (usually another LLM or our own evaluation function) scores them, and then the model updates itself to favor high-scoring answers. OpenAI likely uses Proximal Policy Optimization, or PPO, for this. If you’re not familiar with PPO, it’s a reinforcement learning algorithm that’s been used before in RLHF, the method behind ChatGPT’s behavior tuning, which I covered in a previous video as well. PPO helps the model gradually adjust its responses without making huge, unstable jumps in behavior. It’s basically a way to refine the model without breaking it. This loop runs over and over until the model starts consistently getting good scores. The result? A fine-tuned model that isn’t just copying examples but has actually learned how to answer the way you want. It’s just like how OpenAI’s models always answers your questions with a short introduction, a bullet list and then a short conclusion, or how it doesn’t answer malicious requests. It’s all thanks to their own reinforcement fine-tuning step for the ChatGPT models.
Of course, you don’t just let the model train blindly indefinitely. You need to validate it, making sure it works well on new, unseen examples. If it starts doing well on the training set but flops on new tasks, that’s overfitting — you’ve basically made an AI that’s great at a specific test but terrible at the real-world application. So you hold out some examples for testing and check if the model generalizes well. If not, you tweak things — add more examples, adjust the grading criteria, or fine-tune different parameters.
Now, if you’re wondering how to actually implement this, OpenAI is providing an RFT API that handles a lot of the complexity for you. You just upload your tasks, reference answers, and grading criteria, and the API does the training behind the scenes. But if you wanted to build this yourself, you’d need a reinforcement learning library like Transformer Reinforcement Learning library on Hugging Face (TRL), plus a system to run model inference, calculate rewards, and optimize parameters. It’s more work, but totally possible if you’re into deep AI development or working with open-source models.
Ai2’s open-source work on reinforcement learning with verifiable rewards (RLVR) is also very similar, and you can check out their code at Open Instruct, which I linked below. Just a note here that we expect many libraries and tools and no code fine-tuning options to be built around reinforcement fine-tuning, such as for Deepseek’s impressive and more affordable r1 reasoning model and future ones. I expect Deepmind to also offer reinforcement fine-tuning for its Gemini Thinking models series soon.
At this point, you might be wondering: how is RL fine-tuning different from RLHF, the reinforcement learning method used to align AI with human preferences? The biggest difference is the type of feedback. RLHF relies on human ratings — people ranking answers based on how helpful or appropriate they are. That works well for making AI polite, safe, and generally likable, but it doesn’t necessarily make it factually correct. RFT, on the other hand, is all about objective accuracy. The feedback is more about whether the answer is right or wrong. This makes RFT perfect for domains with strict correctness criteria, like law, medicine, finance, and engineering.
And compared to regular supervised fine-tuning? Standard fine-tuning APIs generally use parameter-efficient supervised fine-tuning methods such as LoRA. We pass in prompts and completions, and the model is tuned by updating model parameters to match the completions. RFT is much more data-efficient. SFT typically requires thousands of examples to get good performance because the model just memorizes input-output mappings. RFT, since it uses iterative feedback, can work with as little as a few dozen carefully chosen examples. Think of it like this: SFT fills your head with information, while RFT teaches how to think through the problem and act on it.
Now let’s talk about some real-world applications. One big use case is expert AI assistants. Imagine a law firm that wants a model capable of handling legal research and case analysis. Instead of just relying on a general AI model that might not fully understand legal nuances, they can use RFT to train a version of o3-mini that knows how to interpret statutes, summarize legal arguments, and answer legal questions with high accuracy. Since the feedback is based on correct legal interpretations, the model learns to be more precise and useful in a professional setting.
Financial risk assessment is another major area. Banks and investment firms rely on complex rules to evaluate loan applications, detect fraud, and assess risk. RFT can help train a model that understands these criteria at an expert level, making accurate, consistent decisions based on historical data. Since the fine-tuning is done with correct past cases, the model learns to apply the same reasoning to new situations, helping automate high-stakes financial decisions.
The real takeaway here is that RFT is about making AI models that are not just good at general reasoning, but truly specialized experts in their domains. And because it requires so much less data than traditional fine-tuning, it’s way more accessible. Instead of needing a huge dataset, you just need a well-designed set of tasks and a solid grading function. That’s a huge win for businesses, researchers, and developers looking to get high performance without massive compute costs.
So, what’s next for RFT? Right now, OpenAI is testing it in an alpha research program with select partners. They’re refining the approach, improving the API, and working with organizations in law, healthcare, and finance to see how well it works in real-world scenarios. As it rolls out more broadly, we could see a whole new wave of domain-specific AI applications. Instead of just having general-purpose models like ChatGPT, we could have fine-tuned specialists in every industry, each optimized for expert-level performance in their respective fields. I expect this to be an extremely powerful addition to the LLM Developer toolkit and to complement other methods we teach in our courses such as Advanced RAG, Prompting, Tool use, and Agents. If you are curious and want to learn more about how to work with RFT and all those techniques, check out our courses on academy.towardsai.net.
I hope you’ve enjoyed the article, and I’ll see you in the next one!
Thank you for reading!