Translate or Edit Text from Images Emulating the Style: TextStyleBrush
This new Facebook AI model can translate or edit every text in the image in your own language, following the same style!


Watch the video and support me on YouTube!
Imagine you are on vacation in another country where you do not speak the language. You want to try out a local restaurant, but their menu is in the language you don't speak. I think this won't be too hard to imagine as most of us already faced this situation whether you see menu items or directions and you can't understand what's written. Well, in 2020, you would take out your phone and google translate what you see. In 2021 you don't even need to open google translate anymore and try to write what you see one by one to translate it. Instead, you can simply use this new model by Facebook AI to translate every text in the image in your own language! This is not even the main application of this technology, but even this is cool. What is even cooler is that their translation tool actually uses similar technology as deep fakes to change the words in an image following the same style as the original words!

It can copy the style of a text from any picture using a single word as an example! Just like this...

This is amazing for photo-realistic language translation in augmented reality. And it’s only the first paper about such a model trained on a new dataset they released for this task, and it is already quite impressive! This could be amazing for video games or movies as you will be able to translate the text appearing on buildings, posters, signs, etc. super easily, making the immersion even more personalized and convincing for everyone based on the chosen language without having to manually photoshop each frame or completely remake scenes. As you can see, it also works with handwriting using a single word as well. Its ability to generalize from a single word example and copy its style is what makes this new artificial intelligence model so impressive. Indeed, it understands not only the typography and calligraphy of the text but also the scene in which it appears whether it's on a curvy poster or different backgrounds.
Typical text-transfer models are trained in a supervised manner with one specific style and use images with text segmentation. Meaning that you need to know what is every pixel in the picture, whether it is the text or not, which is very costly and complicated to have. Instead, they use a self-supervised training process where the style and the segmentation of the texts aren't given to the model during training. Only the actual word content is given. I said that they released a dataset for this model and that it was able to do that with only one word. This is because the model first learns a generalized way of accomplishing the task on this new dataset with many examples during training. This dataset contains approximately 9 000 images of text on different surfaces with only the word annotations.

Then, it uses the new word from the input image to learn its style in what we call a "one-shot-transfer" manner. This means that from only one image example containing the word to be changed, it will automatically adjust the model to fit this exact style for any other words. As you know, the goal here is to disentangle the content of a text appearing on an image and then to use this text's style on new text and put it back on the image. This process of disentangling the text from the actual image is learned in a self-supervised manner, as we will see in a minute.
In short, we take an image as input and create a new image with only the text translated.

Doesn't it feel similar to the task of taking a picture of your face and only change specific features of it to match another style, like the article I published last week on hairstyles? If you remember, I said that it is very similar to how deepfakes work. Which means that what would be better to do this than StyleGan2, the best model for generating images from another image?
Now, let's get into how it can achieve this, which means the training process.
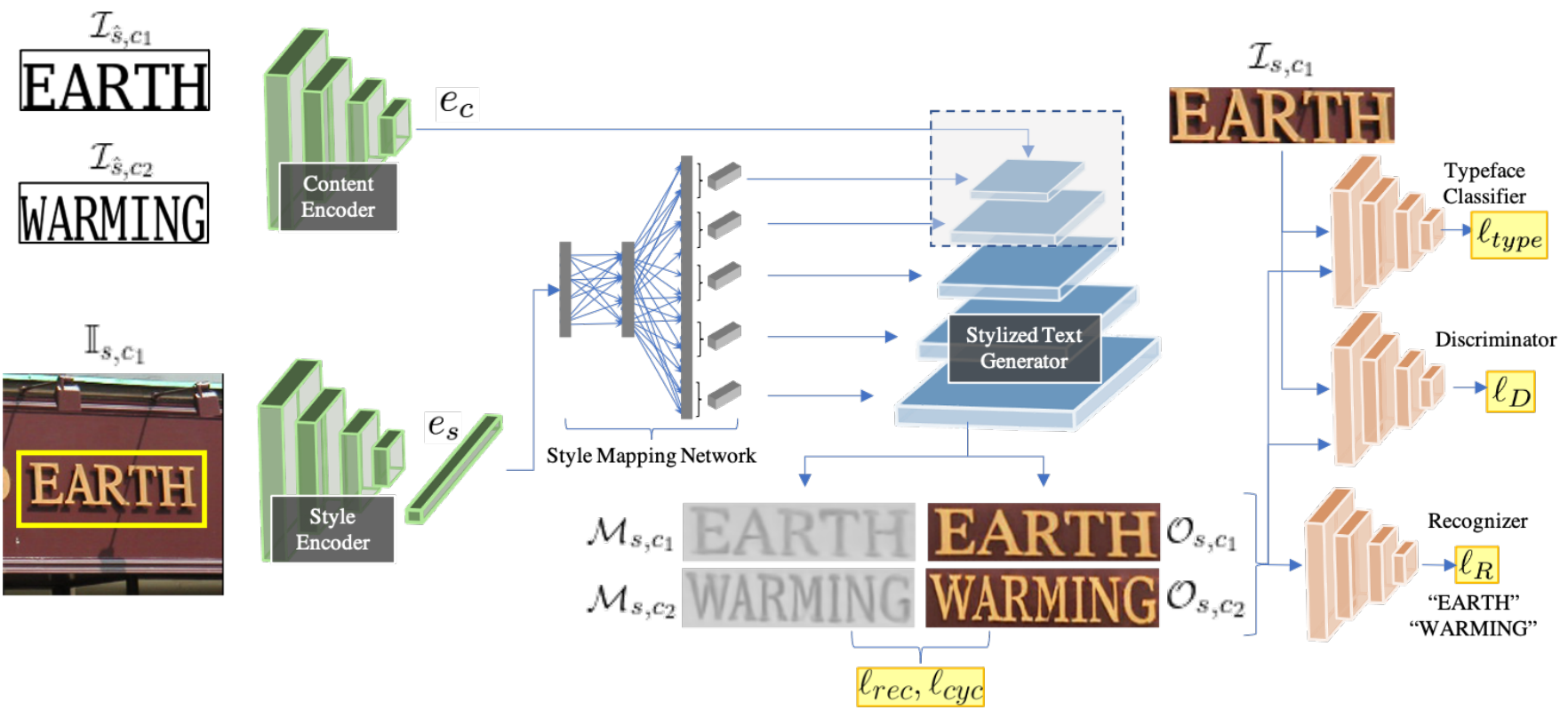
They train this model to measure its performance on these unlabeled images using a pre-trained typeface classification network and text recognition network. This is why it is learning in a self-supervised manner because it doesn't have access to labels or ground truth about the input images directly. This, coupled with a realism measure calculated on the generated image with the new text compared to the input image, allows the model to be trained without supervision where we tell it exactly what is in the image, aiming for photo-realistic and accurate text results. Both these networks will tell how close the generated text is from what it is supposed to be by first detecting the text in the image, which will be our ground truth, and then comparing the new text with what we wanted to write and its font with the original image's text font. Using these two already-trained networks allows the StyleGan-based image generator to be trained on images without any prior labels. Then, the model can be used at inference time, or in other words, in the real world, on any image without the two other networks we discussed, only sending the image through the trained StyleGAN-based network which generates the new image with the modified text. It will achieve its translation by understanding the style of the text and the content separately. Where the style is from the actual image, and the content is the identified string and the string to be generated. Here, the "understanding" process I just referred to is an encoder for each, here shown in green, compressing the information into general information that should accurately represent what we really want from this input. Then, both these encoded, general information are sent in the image StyleGAN-based generator, shown in blue, at different steps according to the details needed. Meaning that the content and style are sent at first because it needs to be translated. Then, we will force the style in the generated image by iteratively feeding it into the network at multiple steps with optimal proportions learned during training. This allows the generator to control low to high-resolution details of the text appearance, instead of being limited to low-resolution details if we only sent this style information as inputs like as it is typically done. Of course, there are more technical details in order to adapt everything and make it work, but I will let you read their great paper linked in the references below if you would like to learn more about how they achieved this in the more technical side of things.
I also wanted to mention that they openly shared some issues with complex scenes where illumination or color changes caused problems, hurting realism just like other GAN-based applications I previously covered transferring your face into cartoons or changing the background of an image. It's crucial and super interesting to see the limitations as they will help to accelerate research.

To end on a more positive note, this is only the first paper attacking this complex task with this level of generalization, and it is already extremely impressive.
I cannot wait to see the next versions! As always, thank you for watching, and many thanks to Rebekah Hoogenboom for the support on Patreon!
Thank you for reading!
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
References
- Praveen Krishnan, Rama Kovvuri, Guan Pang, Boris Vassilev, and Tal Hassner, Facebook AI, (2021), "TextStyleBrush: Transfer of text aesthetics from a single example", https://scontent.fymq3-1.fna.fbcdn.net/v/t39.8562-6/10000000_944085403038430_3779849959048683283_n.pdf?_nc_cat=108&ccb=1-3&_nc_sid=ae5e01&_nc_ohc=Jcq0m5jBvK8AX9p0hND&_nc_ht=scontent.fymq3-1.fna&oh=ab1cc3f244468ca196c76b81a299ffa1&oe=60EF2B81
- Dataset Facebook AI made: https://github.com/facebookresearch/IMGUR5K-Handwriting-Dataset?fbclid=IwAR0pRAxhf8Vg-5H3fA0BEaRrMeD21HfoCJ-so8V0qmWK7Ub21dvy_jqgiVo