Top 10 Computer Vision Papers of 2021
The top 10 computer vision papers in 2021 with video demos, articles, code, and paper reference.


While the world is still recovering, research hasn’t slowed its frenetic pace, especially in the field of artificial intelligence. More, many important aspects were highlighted this year, like the ethical aspects, important biases, governance, transparency and much more. Artificial intelligence and our understanding of the human brain and its link to AI are constantly evolving, showing promising applications improving our life’s quality in the near future. Still, we ought to be careful with which technology we choose to apply.
"Science cannot tell us what we ought to do, only what we can do." - Jean-Paul Sartre, Being and Nothingness
Here are my top 10 of the most interesting research papers of the year in computer vision, in case you missed any of them. In short, it is basically a curated list of the latest breakthroughs in AI and CV with a clear video explanation, link to a more in-depth article, and code (if applicable). Enjoy the read, and let me know if I missed any important papers in the comments, or by contacting me directly on LinkedIn!
The complete reference to each paper is listed at the end of this article.
Subscribe to my newsletter — The latest updates in AI explained every week and please feel free to message me any interesting paper I may have missed!
Tag me on Twitter @Whats_AI or LinkedIn @Louis (What’s AI) Bouchard if you share the list!
Missed last year? Check this out: 2020: A Year Full of Amazing AI papers- A Review
👀 If you’d like to support my work and use W&B (for free) to track your ML experiments and make your work reproducible or collaborate with a team, you can try it out by following this guide! Since most of the code here is PyTorch-based, we thought that a QuickStart guide for using W&B on PyTorch would be most interesting to share.
👉Follow this quick guide, use the same W&B lines in your code or any of the repos below, and have all your experiments automatically tracked in your w&b account! It doesn’t take more than 5 minutes to set up and will change your life as it did for me! Here’s a more advanced guide for using Hyperparameter Sweeps if interested :)
🙌 Thank you to Weights & Biases for sponsoring this repository and the work I’ve been doing, and thanks to any of you using this link and trying W&B!
Access the complete list in a GitHub repository
Watch the 2021 CV rewind
Table of content
- DALL·E: Zero-Shot Text-to-Image Generation from OpenAI [1]
- Taming Transformers for High-Resolution Image Synthesis [2]
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows [3]
- Deep nets: What have they ever done for vision? [bonus]
- Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image [4]
- Total Relighting: Learning to Relight Portraits for Background Replacement [5]
- Animating Pictures with Eulerian Motion Fields [6]
- CVPR 2021 Best Paper Award: GIRAFFE — Controllable Image Generation [7]
- TimeLens: Event-based Video Frame Interpolation [8]
- (Style)CLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis [9]
- CityNeRF: Building NeRF at City Scale [10]
- Paper references
DALL·E: Zero-Shot Text-to-Image Generation from OpenAI [1]
OpenAI successfully trained a network able to generate images from text captions. It is very similar to GPT-3 and Image GPT and produces amazing results.
Short Video Explanation
Short read
 Louis Bouchard
Louis Bouchard
- Paper: Zero-Shot Text-to-Image Generation
- Code: Code & more information for the discrete VAE used for DALL·E
Taming Transformers for High-Resolution Image Synthesis [2]
Tl;DR: They combined the efficiency of GANs and convolutional approaches with the expressivity of transformers to produce a powerful and time-efficient method for semantically-guided high-quality image synthesis.
Short Video Explanation
Short read

Swin Transformer: Hierarchical Vision Transformer using Shifted Windows [3]
Will Transformers Replace CNNs in Computer Vision? In less than 5 minutes, you will know how the transformer architecture can be applied to computer vision with a new paper called the Swin Transformer.
Short Video Explanation
Short read
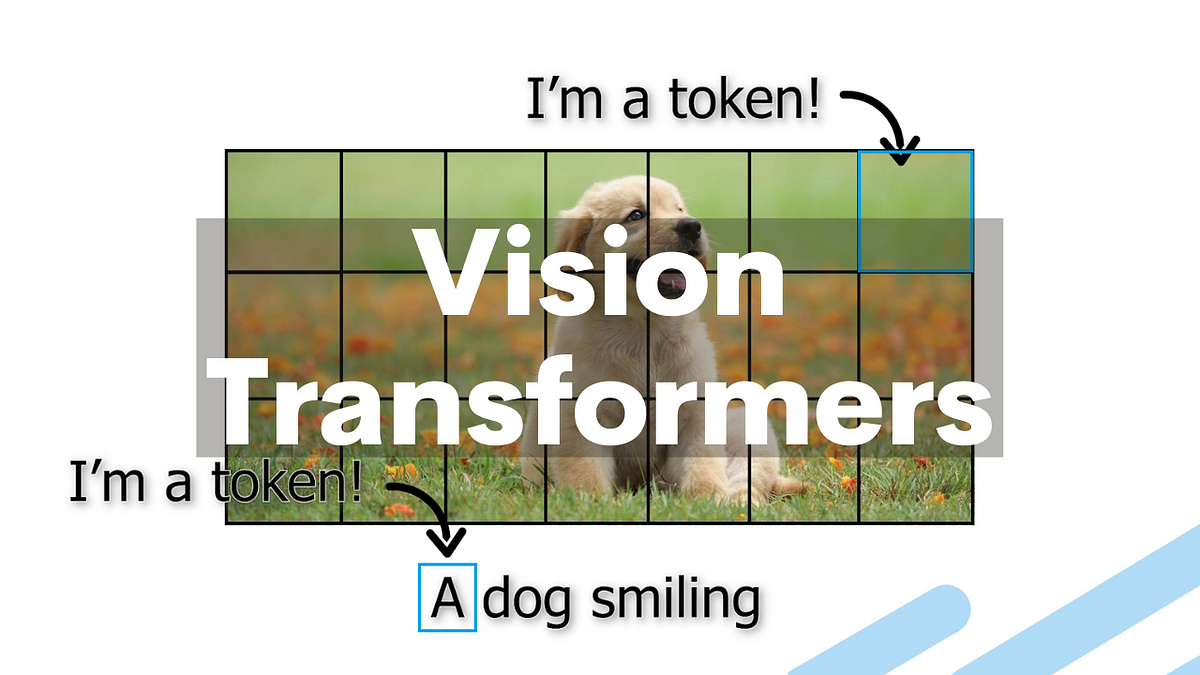
- Paper: Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- Click here for the code
Deep nets: What have they ever done for vision? [bonus]
“I will openly share everything about deep nets for vision applications, their successes, and the limitations we have to address.”
Short Video Explanation
Short read
Louis Bouchard
Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image [4]
The next step for view synthesis: Perpetual View Generation, where the goal is to take an image to fly into it and explore the landscape!
Short Video Explanation:
Short read
Louis Bouchard
- Paper: Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image
- Click here for the code
- Colab demo
Total Relighting: Learning to Relight Portraits for Background Replacement [5]
Properly relight any portrait based on the lighting of the new background you add. Have you ever wanted to change the background of a picture but have it look realistic? If you’ve already tried that, you already know that it isn’t simple. You can’t just take a picture of yourself in your home and change the background for a beach. It just looks bad and not realistic. Anyone will just say “that’s photoshopped” in a second. For movies and professional videos, you need the perfect lighting and artists to reproduce a high-quality image, and that’s super expensive. There’s no way you can do that with your own pictures. Or can you?
Short Video Explanation
Short read
Louis Bouchard
If you’d like to read more research papers as well, I recommend you read my article where I share my best tips for finding and reading more research papers.
Animating Pictures with Eulerian Motion Fields [6]
This model takes a picture, understands which particles are supposed to be moving, and realistically animates them in an infinite loop while conserving the rest of the picture entirely still creating amazing-looking videos like this one…
Short Video Explanation
Short read
Louis Bouchard
CVPR 2021 Best Paper Award: GIRAFFE — Controllable Image Generation [7]
Using a modified GAN architecture, they can move objects in the image without affecting the background or the other objects!
Short Video Explanation
Short read
Louis Bouchard
- Paper: GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields
- Click here for the code
TimeLens: Event-based Video Frame Interpolation [8]
TimeLens can understand the movement of the particles in-between the frames of a video to reconstruct what really happened at a speed even our eyes cannot see. In fact, it achieves results that our intelligent phones and no other models could reach before!
Short Video Explanation
Short read
Louis Bouchard
Subscribe to my weekly newsletter and stay up-to-date with new publications in AI for 2022!
(Style)CLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis [9]
Have you ever dreamed of taking the style of a picture, like this cool TikTok drawing style on the left, and applying it to a new picture of your choice? Well, I did, and it has never been easier to do. In fact, you can even achieve that from only text and can try it right now with this new method and their Google Colab notebook available for everyone (see references). Simply take a picture of the style you want to copy, enter the text you want to generate, and this algorithm will generate a new picture out of it! Just look back at the results above, such a big step forward! The results are extremely impressive, especially if you consider that they were made from a single line of text!
Short Video Explanation
Short read
Louis Bouchard
- Paper (CLIPDraw): CLIPDraw: exploring text-to-drawing synthesis through language-image encoders
- Paper (StyleCLIPDraw): StyleCLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis
- CLIPDraw Colab demo
- StyleCLIPDraw Colab demo
CityNeRF: Building NeRF at City Scale [10]
The model is called CityNeRF and grows from NeRF, which I previously covered on my channel. NeRF is one of the first models using radiance fields and machine learning to construct 3D models out of images. But NeRF is not that efficient and works for a single scale. Here, CityNeRF is applied to satellite and ground-level images at the same time to produce various 3D model scales for any viewpoint. In simple words, they bring NeRF to city-scale. But how?
Short Video Explanation
Short read
Louis Bouchard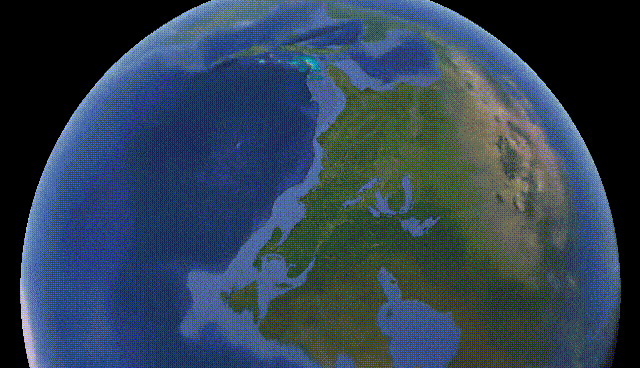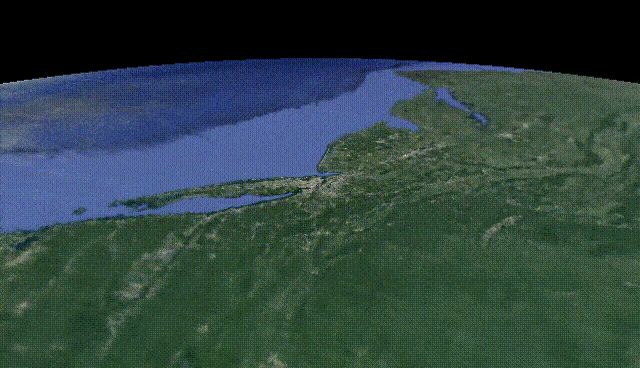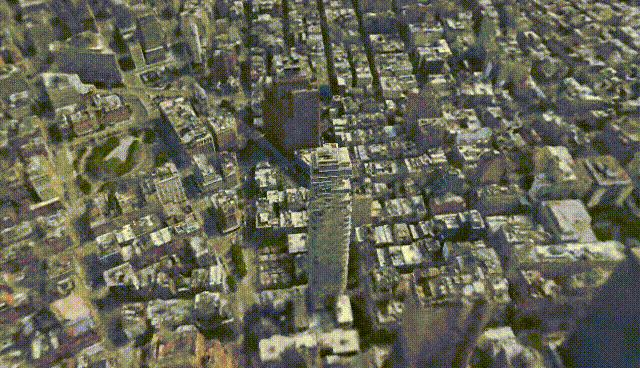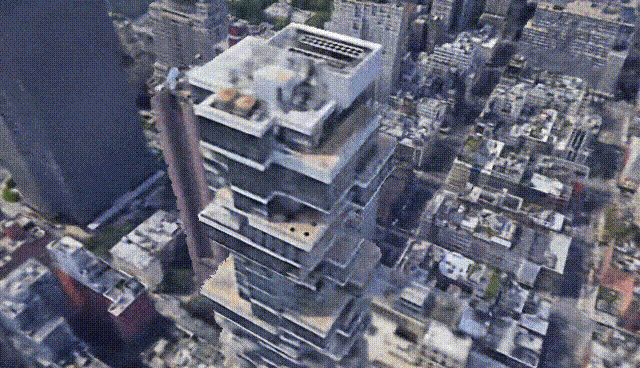
If you would like to read more papers and have a broader view, here is another great repository for you covering 2020: 2020: A Year Full of Amazing AI papers- A Review and feel free to subscribe to my weekly newsletter and stay up-to-date with new publications in AI for 2022!
Tag me on Twitter @Whats_AI or LinkedIn @Louis (What’s AI) Bouchard if you share the list!
Paper references
[1] A. Ramesh et al., Zero-shot text-to-image generation, 2021. arXiv:2102.12092
[2] Taming Transformers for High-Resolution Image Synthesis, Esser et al., 2020.
[3] Liu, Z. et al., 2021, “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows”, arXiv preprint https://arxiv.org/abs/2103.14030v1
[bonus] Yuille, A.L., and Liu, C., 2021. Deep nets: What have they ever done for vision?. International Journal of Computer Vision, 129(3), pp.781–802, https://arxiv.org/abs/1805.04025.
[4] Liu, A., Tucker, R., Jampani, V., Makadia, A., Snavely, N. and Kanazawa, A., 2020. Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image, https://arxiv.org/pdf/2012.09855.pdf
[5] Pandey et al., 2021, Total Relighting: Learning to Relight Portraits for Background Replacement, doi: 10.1145/3450626.3459872, https://augmentedperception.github.io/total_relighting/total_relighting_paper.pdf.
[6] Holynski, Aleksander, et al. “Animating Pictures with Eulerian Motion Fields.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
[7] Michael Niemeyer and Andreas Geiger, (2021), “GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields”, Published in CVPR 2021.
[8] Stepan Tulyakov*, Daniel Gehrig*, Stamatios Georgoulis, Julius Erbach, Mathias Gehrig, Yuanyou Li, Davide Scaramuzza, TimeLens: Event-based Video Frame Interpolation, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, 2021, http://rpg.ifi.uzh.ch/docs/CVPR21_Gehrig.pdf
[9] a) CLIPDraw: exploring text-to-drawing synthesis through language-image encoders
b) StyleCLIPDraw: Schaldenbrand, P., Liu, Z. and Oh, J., 2021. StyleCLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis.
[10] Xiangli, Y., Xu, L., Pan, X., Zhao, N., Rao, A., Theobalt, C., Dai, B. and Lin, D., 2021. CityNeRF: Building NeRF at City Scale.