Top RAG Techniques You Should Know (Wang et al., 2024)
Building the Best RAG Stack: A Breakdown of Wang et al.'s Goldmine Study

Watch the video
Good morning, everyone! This is Louis-Francois, co-founder and CTO of Towards AI and today, we’re diving into what might be the best Retrieval-Augmented Generation (RAG) stack out there — thanks to a fantastic study by Wang et al., 2024. It’s a goldmine of insights for building optimal RAG systems, and I’m here to break it down for you.
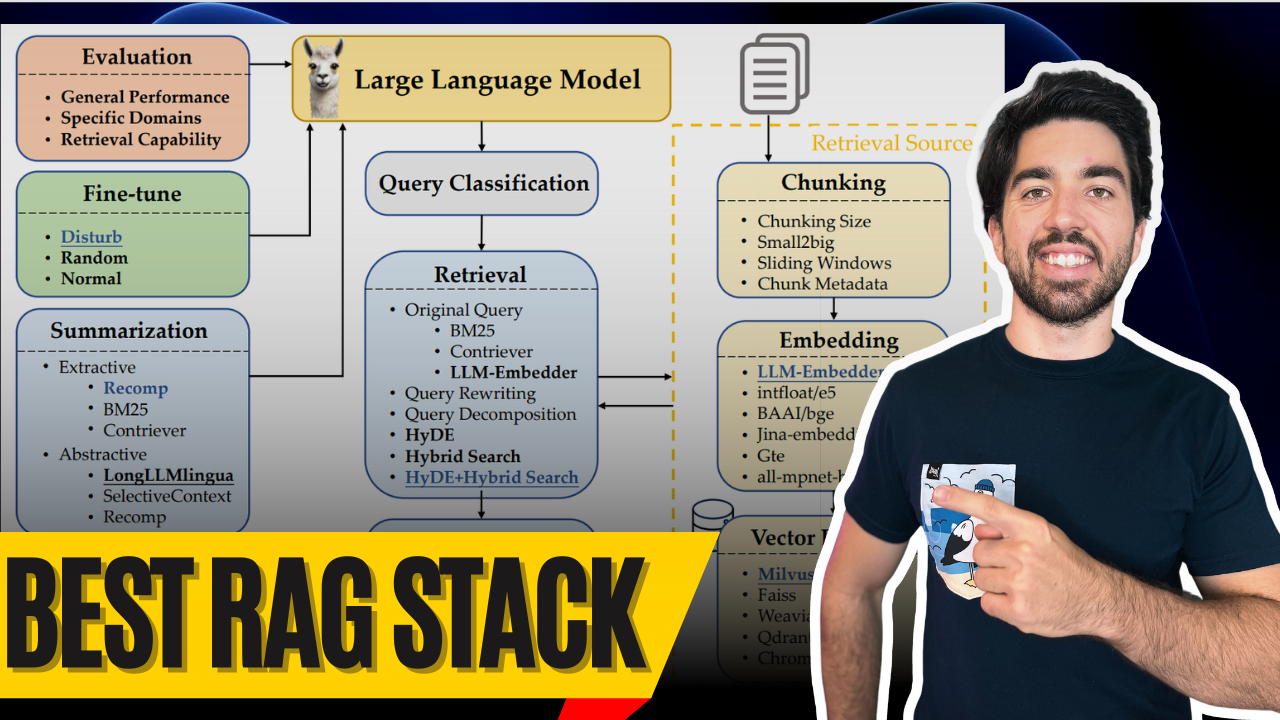
So, what makes a RAG system truly top-tier? The components, right? Let’s go over the best components and how they work so you can also make your RAG system top-tier and finish with a multimodality bonus.
Query Classification
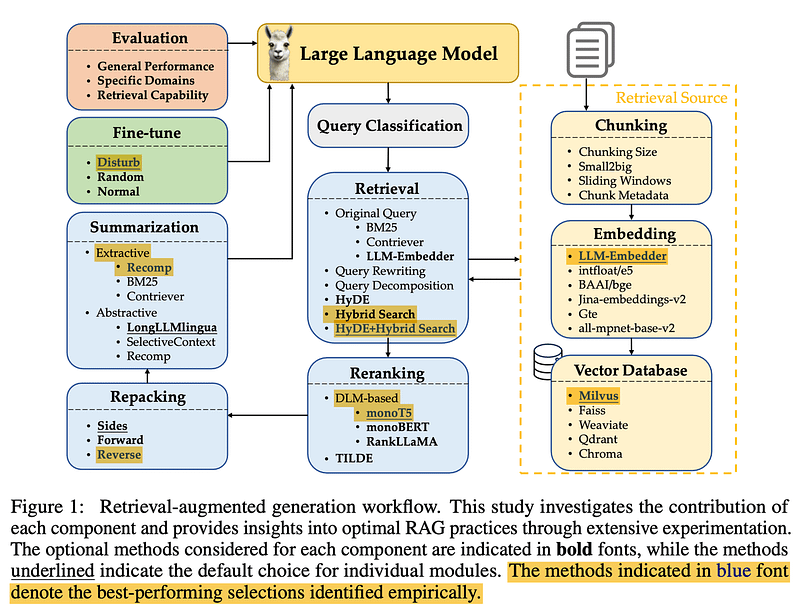
Let’s start with Query Classification. Not all queries are created equal — some don’t even need retrieval because the large language model already knows the answer. For example, if you ask “Who is Messi?” the LLM’s got you covered. No retrieval needed!
Wang et al. created 15 task categories, determining whether a query provided sufficient information or if retrieval was necessary. They trained a binary classifier to separate tasks, labeling “sufficient” where it needed no retrieval and “insufficient” when retrieval was needed. In this image, Yellow means no need, and red means to go fetch some docs!
Chunking
Next up: Chunking. The challenge here is finding the perfect chunk size for your data. Too long? You add unnecessary noise and cost. Too short? You miss out on context.

Wang et al. found that chunk sizes between 256 and 512 tokens worked best. But remember, this varies by data — so be sure to run your evaluations! Pro tip: use small2big (start with small chunks for search, then move to larger chunks for generation), or try sliding windows to overlap tokens between chunks.
Metadata & Hybrid Search
Leverage your metadata! Add things like titles, keywords, or even hypothetical questions. Pair that with Hybrid Search, which combines vector search (for semantic matching) and good ol’ BM25 for traditional keyword search, and you’re golden.
HyDE (generating pseudo-documents to enhance retrieval) is cool and leads even better results but super inefficient. For now, stick with Hybrid Search — it strikes a better balance, especially for prototyping.
Embedding Model
Choosing the right embedding model is like finding the perfect pair of shoes. You don’t want soccer shoes for playing tennis. LLM-Embedder from FlagEmbedding was the best fit for this study — great balance of performance and size. Not too big, not too small — just right.
Just note that they only tested open-source models, so Cohere and OpenAI were out of the game. Cohere is probably your best bet otherwise.
Vector Database

Now for the database. For long-term use, Milvus is their go-to vector database. It’s open-source, reliable, and a great option for keeping your retrieval system running smoothly. I also linked it in in the description below.
Query Transformation
Before retrieval, you’ve got to transform those user queries! Whether it’s through query rewriting for clarity, query decomposition for breaking down complex questions into smaller ones and retrieving for each sub-question, or even generating pseudo-documents (as HyDE does) and use them in the retrieval process — this step is crucial for improving accuracy. Just remember, more transformation can add latency, especially HyDE..
Reranking
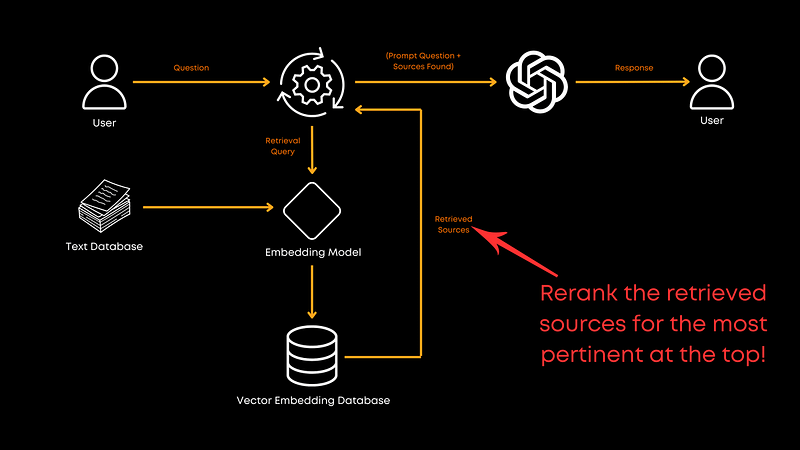
Now let’s talk about Reranking. Once you retrieve documents, you need to make sure the most relevant ones are at the top of the pile. That’s where reranking comes in.
In this study, monoT5 stood out as the best option for balancing performance and efficiency. It fine-tunes the T5 model to reorder documents based on their relevance to the query, ensuring the best match comes first. RankLLaMA gave the best performance overall, but TILDEv2 was the fastest. There are more information about each in the paper if you are interested.
Document Repacking
After reranking, you’ll need to do some Document Repacking. Wang et al. recommend the “reverse” method, where documents are arranged in ascending order of relevance. Liu et al. (2024) found that this approach — putting relevant information at the start or end — boosts performance. Repacking optimizes how the information is presented to the LLM for generation after the reranking process happens to help the LLM better make sense of the provided information in a better order vs. the theoretical relevant order.
Summarization

Then, before calling the LLM you want to cut the fluff with Summarization. Long prompts sent to the LLM are expensive and often unnecessary. Summarization will help remove redundant, or unnecessary information and reduce costs.
Use tools like Recomp for extractive compression to selects useful sentences and abstractive compression to synthesizes information from multiple documents. But, if speed is your priority, you might consider skipping this step.
Fine-tuning the Generator
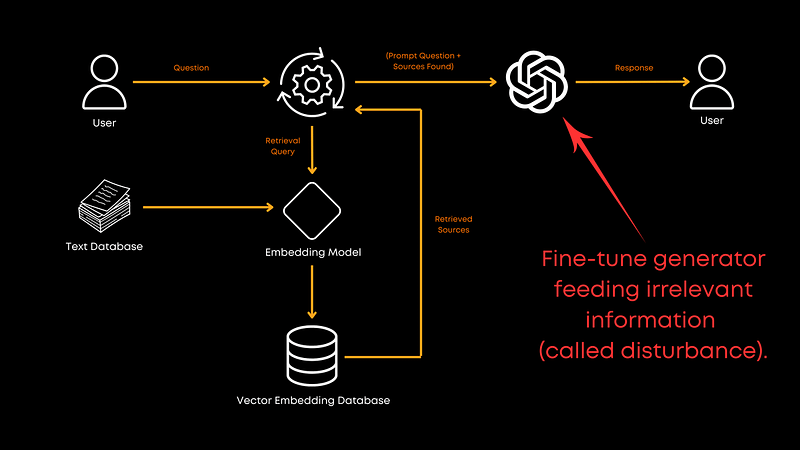
Lastly, should you fine-tune the LLM you are using for generation? Absolutely! Fine-tuning with a mix of relevant and random documents improves the generator’s ability to handle irrelevant information. It makes the model more robust and helps it give better responses overall. No exact ratio was provided in the paper, but the results were clear: fine-tuning is worth the effort! Still, it obviously depends on your domain as well.
Multimodalities
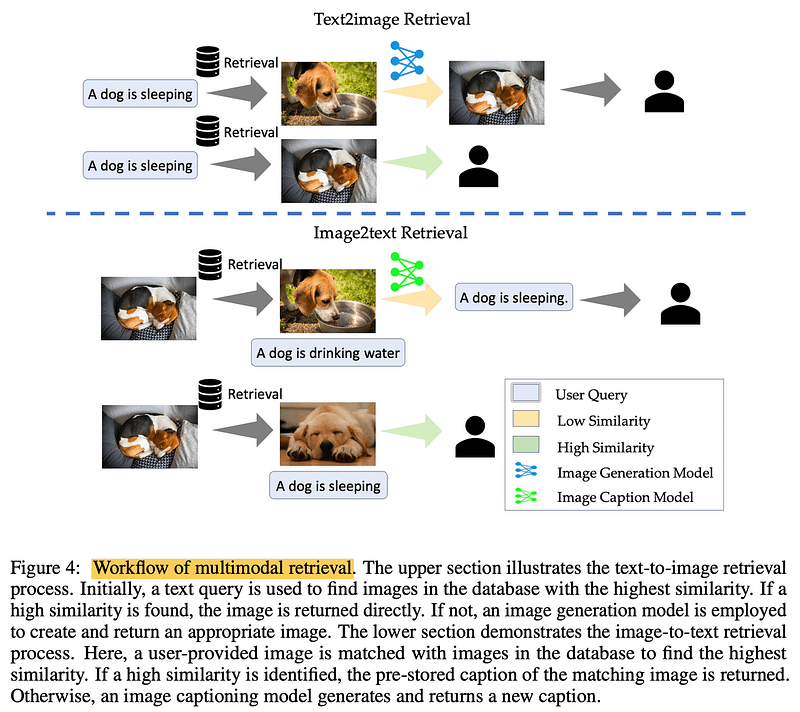
Dealing with images? Implement Multimodal retrieval. For text-to-image, querying a database for similar images speeds up the process. In image-to-text, matching similar images retrieves accurate, pre-stored captions. It’s all about groundedness — retrieving real, verified information.
Conclusion
In short, this paper by Wang et al. gives us a solid blueprint for building an efficient RAG system. Keep in mind, though, that this is just one paper and doesn’t cover every aspect of the RAG pipeline. For example, joint training of retrievers and generators wasn’t explored and could unlock even more potential. They also didn’t dive deep into chunking techniques due to costs, but that’s a direction worth exploring.
I highly recommend checking out the full paper for more information. We also recently released our book “Building LLMs for Production,” which is full of RAG and fine-tuning insights, tips and practical examples to help you build and improve your LLM-based systems. The link is also in the description below for both the physical book and e-book versions.
And as always, thank you for reading. If you found this breakdown helpful or have any comments, please let me know in the comments below, and I’ll see you in the next one!
References
Building LLMs for Production: https://amzn.to/4bqYU9b
Wang et al., 2024 (the paper reference): https://arxiv.org/abs/2407.01219
LLM-Embedder (embedding model): https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder
Milvus (vector database): https://milvus.io/
Liu et al., 2024 (document repacking): https://arxiv.org/abs/2307.03172
Recomp (summarization tool): https://github.com/carriex/recomp